Table of Contents
Imagine Managing Your Campus Network Like This
You are away from your desk, having a coffee, when your colleague calls you: “The core business system is experiencing serious latency. I’ve already checked the physical cables and the optical module Tx/Rx power, and everything looks fine. You need to take over and continue the troubleshooting.“
In a traditional setup, panic begins immediately. You would need to find Wi-Fi, open your laptop (sometimes even rush back to the office to get your computer), connect to a clunky VPN, log into multiple switch/router CLIs, and manually sift through thousands of ACL rules and QoS queues.
Now imagine a different approach. You simply take out your phone, open Telegram, and type: “Check the real-time traffic rate on switch 192.168.1.209 for me ? We’re experiencing some network latency.“
Within seconds, your phone receives a neat, structured response directly from the network gateway, like this:
You reply on Telegram: “Limit guest network bandwidth to 10 Mbps and prioritize corporate finance traffic.“
“Policy applied successfully via RESTful API. Congestion cleared.” Your laptop stays in your bag. The issue is resolved in under 60 seconds, right from your chat app.
This is not a conceptual mockup for the distant future. We have already built it, leveraging AI in campus network management to realize agentic operations. By leveraging the local Hermes Agent framework and quantized LLMs directly on the Asterfusion ET2500 series intelligent gateway, our engineers can manage production SONiC router operations natively.
But as a network engineer or CIO, your next pragmatic question is: “Running Large Language Models (LLMs) like OpenClaw or Kimi for real-time network telemetry burns tokens at an astronomical rate. How can we afford the API costs, let alone handle data privacy?”
Here is our answer: We enable local token generation right at the network edge AI gateway, and cut AI token usage by up to 100%.
The Engineering Bottleneck: Why Remote AI Sucks at NetOps
OpenClaw has recently gained massive traction in the developer community. Many users are excited about running it on remote cloud servers, expecting this AI strategist to automate their enterprise networks.
But in real-world network operations, a harsh engineering bottleneck quickly appears: Remote compute has zero native awareness of the local network.
No matter how capable an LLM is, it is constrained by its context window. If you want it to troubleshoot micro-burst latency or abnormal traffic, what is your input model? Are you going to stream massive, raw PCAP packet captures and tens of thousands of NetFlow logs directly to a cloud API?
- The Privacy Nightmare: Sending raw corporate traffic to public cloud LLMs creates severe data sovereignty and compliance issues.
- The Token Burn: Raw logs are incredibly noisy. Dumping raw byte streams into an LLM burns through expensive API tokens at high speed, while heavily increasing the chance of AI “hallucinations” caused by noisy data.
Large models need high-quality context, not raw data. Networks need an edge intelligence layer that acts as a translator for LLMs.
The “Ideal Host” for OpenClaw — ET2508 Hardware Specification
To be clear, when we designed the ET2508 as an open intelligent gateway, we did not anticipate the rapid rise of OpenClaw. The original goal was straightforward and engineering-driven: build a carrier-grade edge gateway with true hardware–software decoupling and converged compute capabilities.
The ET2500 is based on an 8-core ARM64 N2 processor, equipped with 16 GB DDR5 memory by default (expandable up to 48 GB via plug-in modules). Running an open system with native support for standard Linux distributions like Ubuntu and Debian, it provides a perfect environment for hosting quantized open-source models in the 7B to 14B parameter range locally and stably.
A Free Local “Token Production Line” for OpenClaw
On ET2508, simply deploying the model is only the first step. The real engineering challenge is how to keep it properly “fed.” Directly passing raw network byte streams into a large model quickly exhausts the context window and drives API costs out of control.
This requires the gateway to do more than host the model. It must also take responsibility for upstream data cleansing and feature extraction. At this stage, ET2508 shows the strength of a true open hardware foundation.
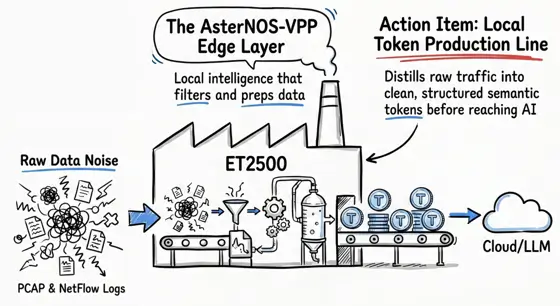
First, it provides native and rich high-quality data sources. The underlying AsterNOS-VPP system natively supports NetFlow and IPFIX-based traffic sampling. In addition, thanks to the open Ubuntu environment, tools such as ntopng and Snort can run directly on the gateway, enabling full packet visibility at the network edge.
Second, it offers a powerful hardware-accelerated pipeline. Through its M.2 interface, the ET2508 can integrate AI acceleration modules ranging from 26 TOPS up to 40 TOPS. This level of edge compute is sufficient to run lightweight feature extraction models locally.
As raw traffic flows through this pipeline, it is aggressively and efficiently denoised, filtered, and reduced in dimensionality. Unnecessary low-level heartbeat packets are removed. Thousands of repetitive malicious scans are compressed into a single structured JSON-style semantic token, for example:
{"event_type": "abnormal_scan", "source_ip": "192.168.1.50", "action": "blocked"}
This local transformation significantly helps reduce OpenClaw token costs by compressing raw telemetry into semantic tokens.
No sensitive data needs to be sent to the cloud, and no expensive API calls are required. In this architecture, ET2508 itself becomes a local token production line, continuously feeding refined network intelligence in real time to the OpenClaw model running on the same device.
Closing the Loop: From Conversation to Line-Rate Execution
Once OpenClaw processes this clean, localized context, it makes an intelligent reasoning decision. But it doesn’t stop at talking.
Through the standardized RESTful APIs exposed by Asterfusion’s open platform, OpenClaw converts its natural language decisions back into precise network configurations. Whether it’s spinning up a QoS queue, modifying an ACL rule, or triggering traffic steering, the policy is pushed down instantly to the underlying AsterNOS-VPP forwarding plane, which boasts up to 60 Gbps of routing capacity.
“Today’s infrastructure can’t meet the demands of powering AI at scale” said Jeetu Patel, President and Chief Product Officer at Cisco.
As AI agents continue to evolve, inference and decision-making are increasingly shifting closer to where user interactions actually occur — including coffee shops, retail stores, factory floors, and other edge environments.
Network operations are undergoing the same transformation. The value of ET2500 is that it makes this shift toward edge intelligence far easier to deploy, more operationally practical, and scalable for mass rollout as demand grows.
Stay Tuned
Our team is continuously expanding the capabilities of this localized AI assistant, feeding our local Hermes Agent with comprehensive SONiC command documents, sonic-ops automated skills, and benchmark evaluation data from multiple LLMs for continuous performance validation.




We will be sharing a deep-dive engineering guide soon, detailing the exact step-by-step setup of our Asterfusion ET2500 Agent + Telegram deployment. Stay tuned as we keep pushing the boundaries of edge network automation!
Contact us and share your requirements, and we will help you identify the most suitable setup.
Request a demo or need assistance ?
Fill out the form, and we’ll reach out to you today !



