Table of Contents
Recently, Asterfusion unveiled the ET2500 open smart gateway, a cutting-edge device that promises to revolutionize network performance. This compact powerhouse is driven by Vector Packet Processing (VPP) technology and features a robust Marvell OCTEON 10 ARM Neoverse2 8-core processor. With this configuration, the ET2500 achieves an impressive routing performance of up to 48Gbps, even when managing a full BGP routing table of approximately 1 million entries.
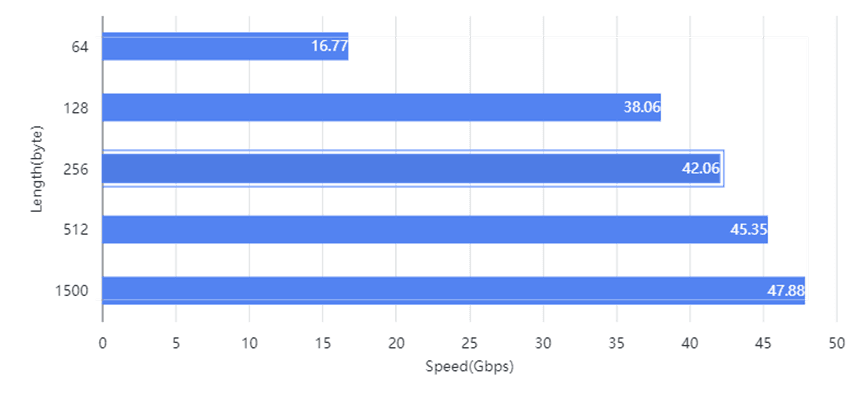
This capability is sufficient to handle traffic equivalent to 3,000 concurrent 4K video calls, making it ideal for enterprises, small metro networks, and cloud edge gateways. Remarkably, the ET2500 outperforms similar gateway devices that lack VPP by more than tenfold. But what exactly enables VPP to deliver such a significant performance boost? Let’s explore this together!

Understanding Vector Packet Processing (VPP)
Vector Packet Processing (VPP) is a key component of the Fast Data – Input/Output (FD.io) project under the Linux Foundation. Its primary aim is to provide a high-speed layer 2-4 user-space network stack that operates on common architectures such as x86, Arm, and Power
VPP processes the largest available vector of packets from the network IO layer and efficiently routes them through a Packet Processing graph. By integrating with the Data Plane Development Kit (DPDK), VPP can directly access hardware network card resources, enhancing its processing capabilities.
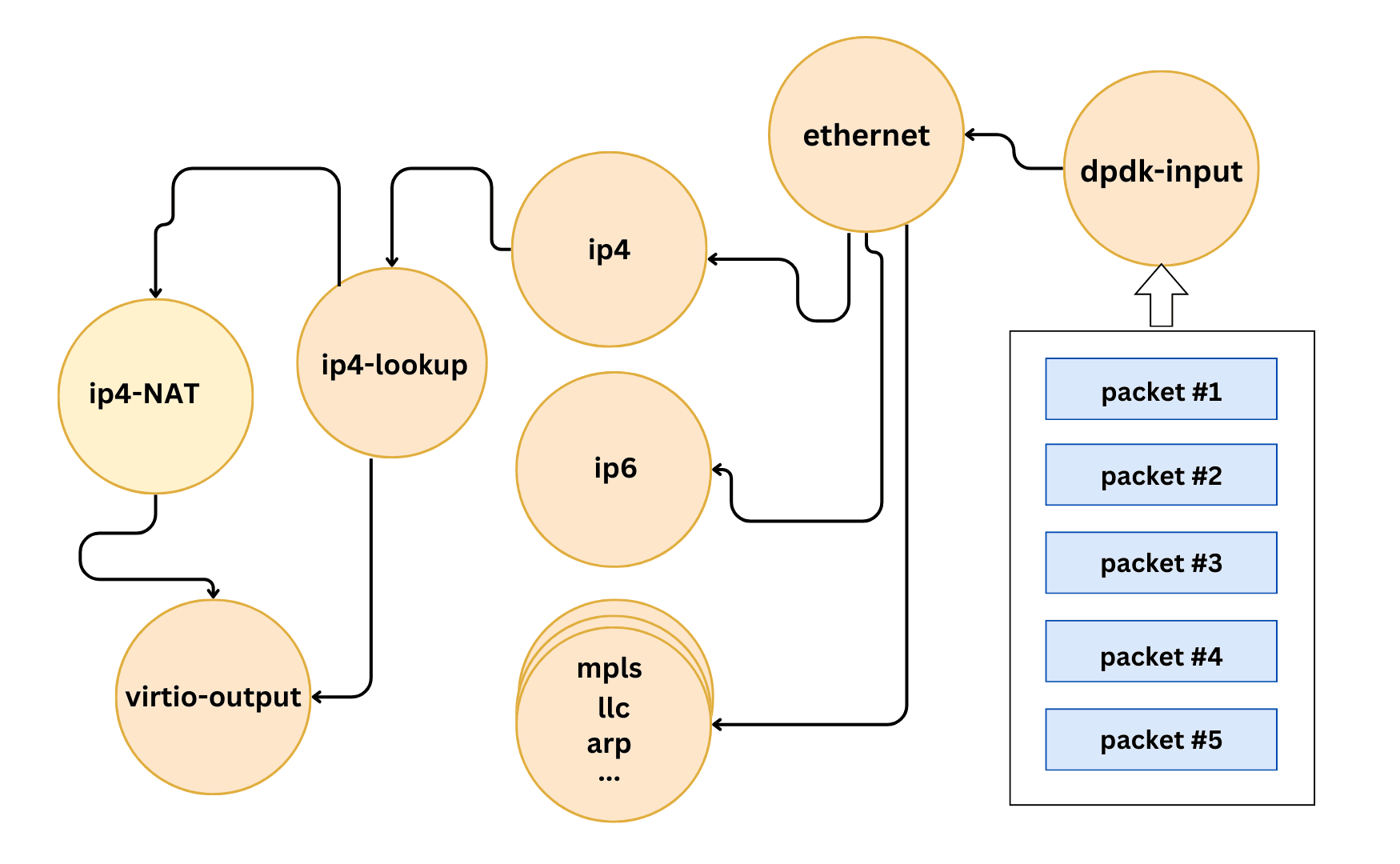
Why Choose Vector Processing Over Traditional Scalar Processing?
Traditional scalar processing handles packets one at a time, which can lead to inefficiencies, especially under high network I/O conditions. In contrast, vector processing offers several advantages:
- Batch Processing of Multiple Packets: VPP groups packets into a “vector” and processes them simultaneously at each node. This approach reduces the overhead of resource preparation and context switching, significantly boosting per-packet processing speed.
- Utilizing SIMD Parallel Processing: Modern CPUs support Single Instruction Multiple Data (SIMD), allowing a single instruction to operate on multiple data points simultaneously. This parallelism greatly enhances processing speed compared to the scalar model. For instance, the Marvell OCTEON 10 ARM Neoverse N2 processors with Scalable Vector Extensions Version 2 (SVE2) can handle flexible vector lengths, processing up to 64 IPv4 addresses in a single instruction at the 2048-bit configuration.
- Optimizing Cache Usage: Vector processing leverages modern CPUs’ large L1/L2 caches to load multiple packets simultaneously, minimizing the need for frequent memory access. For example, the Marvell OCTEON 10 ARM Neoverse N2 processor’s 64KB L1 cache can store approximately 42 full 1500-byte packets or 3276 IPv4 headers at once, reducing cache-memory swaps and enhancing packet processing efficiency.
In summary, vector packet processing harnesses batch processing, SIMD parallelism, and optimized cache utilization to significantly enhance processing speed, making it exceptionally well-suited for high-performance networking environments.
Optimizing Network Performance: Traditional Linux Stack vs. VPP
In the realm of high-performance networking, the traditional Linux network stack and Vector Packet Processing (VPP) represent two distinct approaches to packet processing. Understanding their differences is crucial for optimizing network performance.
Challenges with the Traditional Linux Network Stack
The traditional Linux network stack operates within kernel space, prioritizing generality and software flexibility. However, it faces several bottlenecks in high-performance environments:
- Kernel-to-User Space Switching Overhead: Network data processing often requires frequent switches between user space and kernel space, introducing significant latency, especially under high traffic conditions.
- Layered Processing Overhead: The stack processes data layer-by-layer according to the OSI model. Each layer involves protocol parsing and data copying, which can lead to inefficiencies.
- Soft Interrupts and Single-Thread Limitations: The Linux kernel’s reliance on soft interrupts and single-threaded processing limits its ability to fully utilize multi-core CPUs. Even with Receive Side Scaling (RSS) distributing data flows across multiple cores, scheduling and synchronization overheads prevent full parallel processing.
Advantages of VPP’s User-Space Network Stack
VPP’s host stack, a user-space implementation of various transport, session, and application layer protocols, addresses these issues through several innovative methods:
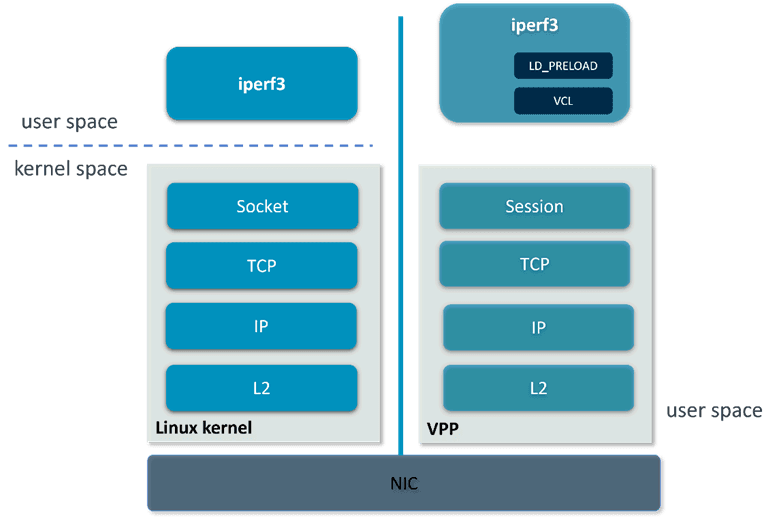
- Reducing Context Switching: By operating in user space, VPP eliminates the need for kernel-to-user space switching. It leverages the Data Plane Development Kit (DPDK) to directly access network cards, bypassing the kernel network stack.
- Integrated Protocol Processing: VPP combines protocol layers such as TCP, IP, and Session, minimizing redundant data transfers. This integration allows protocol processing to occur in the same memory area, reducing the need for repeated data copying.
- User-Space Multi-Threaded Processing: Unlike the kernel’s single-threaded model, VPP fully utilizes modern multi-core CPUs by processing multiple data flows in parallel through a user-space thread pool. This approach reduces thread scheduling overhead and allows for more flexible task allocation, resulting in nearly linear improvements in throughput.
What is Data Plane Development Kit (DPDK)?
The Data Plane Development Kit (DPDK) is an open-source project that provides user-space libraries and drivers to enhance packet processing speeds across various CPU architectures like Intel x86, ARM, and PowerPC.
The Synergy of DPDK and VPP
DPDK bypasses the Linux kernel[[ii]], performing packet processing in user space to maximize networking performance. DPDK achieves this through the use of a Poll-Mode Driver (PMD) running in user space, that continually checks incoming packet queues to see if new data has arrived, achieving both high throughput and low latency. PMD works in data-link layer (Layer 2).
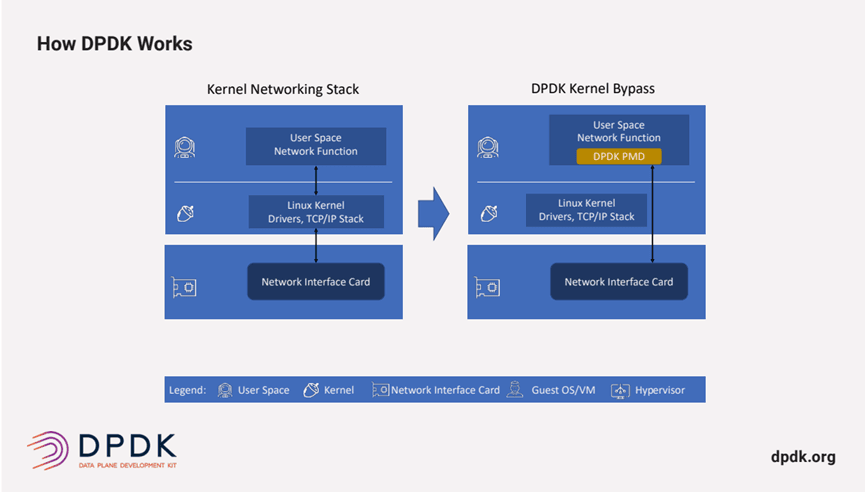
VPP focuses on networking protocols from Layer 2 to Layer 7 and uses DPDK as its network driver. This integration combines the L2 performance of DPDK with VPP’s agility across L3 to L7.
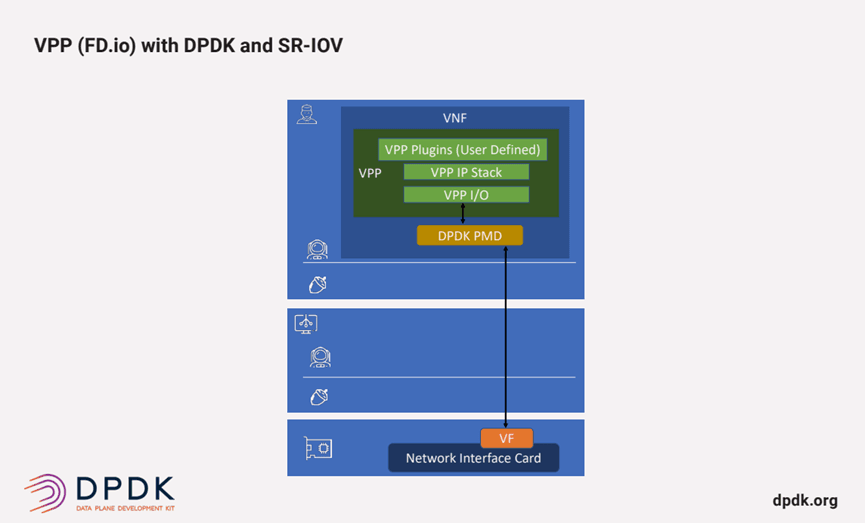
- Direct Hardware Access: VPP uses DPDK to directly access network hardware, avoiding kernel-to-user space context switching and eliminating most kernel-related overhead.
- Direct Memory Access: VPP leverages DPDK’s memory mapping to reduce memory copies and context switches, enabling direct access to network buffers without kernel involvement.
Through this integration, VPP achieves a complete user-space network stack, significantly enhancing network processing performance.
Asterfusion Marvell OCTEON Tx-based Open Network Platforms Powered by VPP
In summary, VPP, as an open-source technology, delivers performance levels traditionally associated with specialized network hardware and professional network operating systems on general-purpose CPUs. This brings the benefits of open network technology to a wide range of users with exceptional cost-effectiveness.
The Asterfusion Marvell OCTEON Tx-based open network platform exemplifies the practical application of this technology. Asterfusion, an open network solution leader in the industry since 2017, has extensive experience with Marvell OCTEON products, helping numerous customers meet their unique needs. Trust us to deliver tailored solutions for your specific requirements—contact us today!

Reference:
[1] https://bgp.potaroo.net/as2.0/bgp-active.html
[1] https://developer.arm.com/documentation/102099/0003/Scalable-Vector-Extensions-support
[1] https://dataplane-stack.docs.arm.com/en/nw-ds-2023.05.31/user_guide/tcp_term.html



