
- Improve IOPS
Read performance increased by 3-6%, and write performance increased by 6-10%. - Reduce I/O Latency
Read latency is reduced by 3–6%, and write latency decreases by up to 10%. - Lossless Transport
RoCEv2 with PFC, ECN, and DCBX ensures zero packet loss, delivering high throughput for storage traffic. - Congestion Free
INT-driven Adaptive Routing measures real-time link utilization and dynamically bypasses congested paths to minimize tail latency for storage workloads.
Test Result
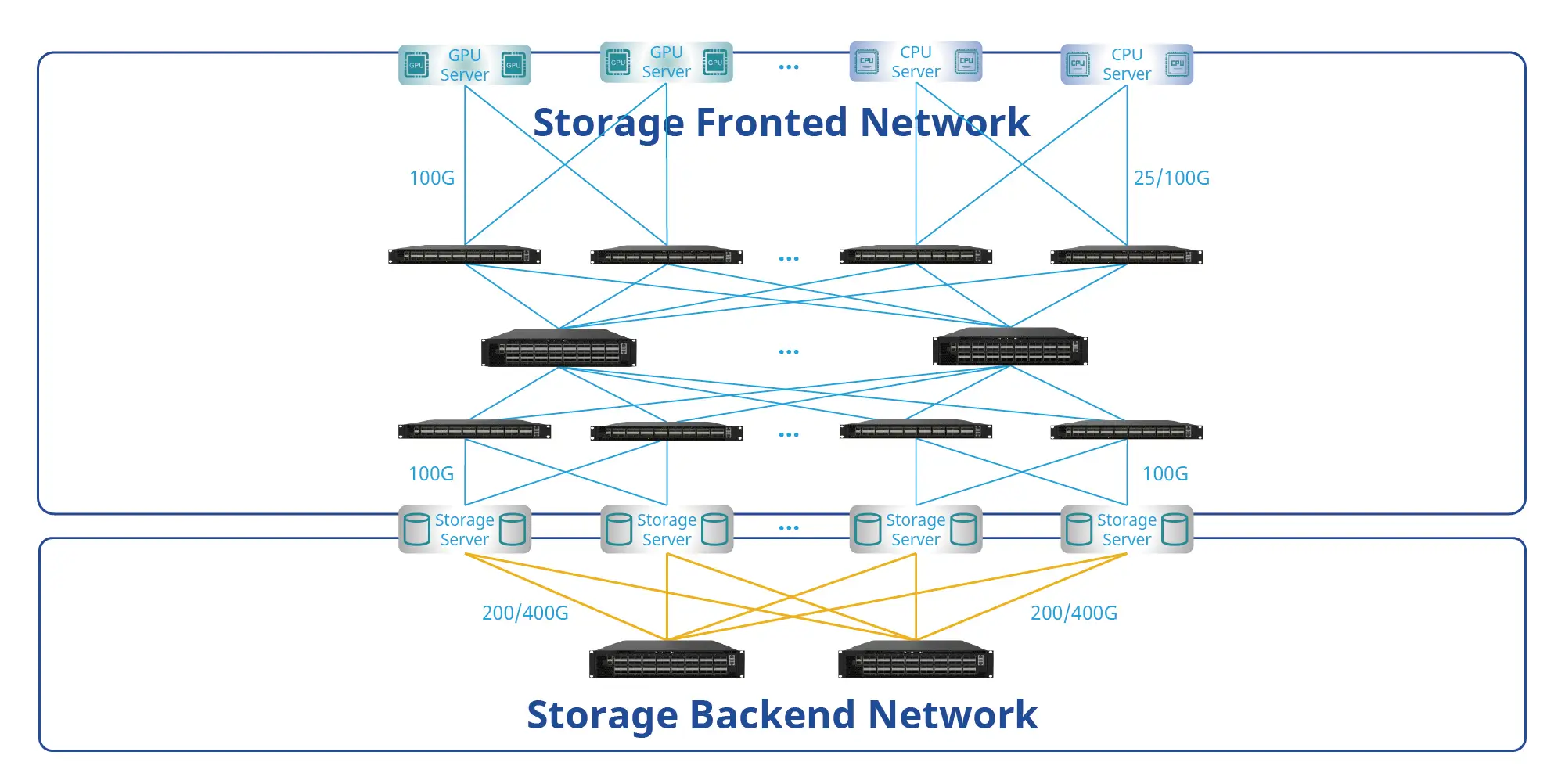
Using the ultra-low-latency CX-532P-N RoCE switch, two compute nodes and two NVMe-oF storage nodes were interconnected via ConnectX-5 adapters. Storage performance was evaluated with vdbench 5.04.06 and fio 2.1.10 (4KB/8KB random workloads), and results were compared against a Mellanox SB7700 InfiniBand switch.

In single compute–storage node latency tests, the RoCE switch reduced read latency by up to 6.3% and write latency by up to 10.1% compared with the InfiniBand switch.

In multi-flow concurrent IOPS tests between two compute nodes and two storage nodes, read IOPS improved by up to 6.1% and write IOPS improved by up to 10.5%.



{kind=link}