Table of Contents
Introduction
Operations and technical leads at AI companies often face a common challenge: even with fully equipped NCCL NVIDIA GPU clusters, uneven workload distribution can lead to low utilization of computing resources. According to a test report by Xingrongyuan, under the traditional ECMP five-tuple hash mode, bandwidth utilization reaches only 84.5%, meaning that “the computing power of 10 GPUs cannot be fully leveraged.” In contrast, enabling INT-Based Routing increases bandwidth utilization to 97%, and with support from the Asterfusion CX864E-N low-latency switch, end-to-end network latency drops to 2μs. The key technology driving this improvement is ARS (Adaptive Routing and Switching).
Ⅰ. Traffic Bottlenecks in NCCL Clusters
NVIDIA Collective Communications Library (NCCL) enables efficient multi-GPU and multi-node communication in AI and deep learning workloads, providing a high-performance NCCL networking layer for cluster communication. NCCL amplifies computing power through multi-node GPU collaboration, but as data moves between nodes, it generates a large number of “macro flows.” In a Spine-Leaf topology, these flows can easily cause some links to become overloaded while others remain underutilized due to rigid routing. Even the busiest links often struggle to exceed 90% bandwidth utilization under uneven load conditions.
The ECMP test results in the report illustrate this clearly: even with an optimized ECMP QP Hash mode, bandwidth utilization in a 2-node × 8-GPU setup reaches only 88.05%. For AI development teams, this means that the expensive GPUs’ computing power cannot be fully leveraged, leading to training delays and underutilized hardware investments.
About How to Read NCCL Test Results and What Really Matters for AI Clusters
Ⅱ. How ARS Solves Traffic Issues in NCCL Clusters
Flowlet-based adaptive routing (ARS) is the core technology behind INT-Based Routing. In load-balancing scenarios, it first breaks down macro flows into smaller, lightweight flowlets. Then, leveraging real-time link awareness, it dynamically assigns paths for these flowlets to optimize network utilization.
In tests using the Asterfusion CX864E-N ultra-low-latency switch, a network was set up with two switches as Leafs and one as Spine, with INT-Based Routing and ARS enabled under an ECMP scenario. By splitting large flows into flowlets and dynamically adjusting their paths, this technology reduces both link congestion and underutilization. Real-time route adjustments allowed bandwidth utilization to reach 97%, well above the Ultra Ethernet Consortium (UEC) target of 85%, clearly demonstrating the advantages of INT-Based Routing and ARS in enhancing data center network performance.
Want to learn more about Adaptive Routing and Switching (ARS)?
🔗Click here: ARS on SONiC Stops Elephant Flow-Induced Network Latency in Data Centers
Ⅲ. Real-world Test Data Validating ARS Optimization
These results are not just “lab experiments”; extensive NCCL tests were conducted using the Keysight AresONE-S 400GE tester and Asterfusion CX864E-N switches, fully replicating the Spine-Leaf topology of AIDC and covering real-world scenarios from 2-node × 8-GPU to 8-node × 2-GPU setups:

Multi-topology adaptability
Whether it’s a 4-node × 4-GPU or 8-node × 2-GPU configuration, bandwidth utilization under INT-Based Routing with ARS consistently remains around 97%, far exceeding the 80%-88% achieved with ECMP.
Resilience under extreme conditions
Even with a non-ideal 1:0.5 convergence ratio (uplink bandwidth pressure), actual bandwidth utilization still reaches 96.88%. Compared with the traditional 1:1 convergence ratio achieving 84.5%, congestion tolerance is improved by approximately 15%.
Full communication mode coverage
For NCCL’s core communication patterns such as All-Reduce and All-to-All, performance approaches the ideal “back-to-back benchmark,” demonstrating that ARS can effectively handle complex AI workloads.
Ⅳ. Practical Benefits
For operations engineers, troubleshooting NCCL cluster stalls used to require capturing and analyzing traffic on each link to identify load imbalance—a process that could take half a day or more. With ARS, traffic is automatically split into flowlets, implementing flowlet load balancing to optimize link utilization, and INT telemetry provides real-time link monitoring.
In a 2-node × 8-GPU setup, link bandwidth utilization rises from 84.5% to 96.88%. Balanced bandwidth and the absence of hidden congestion mean engineers no longer need to stay overnight monitoring the cluster, and troubleshooting time is significantly reduced. Buffer utilization curves in Grafana dashboards also remain smooth, avoiding the frustrating spikes and drops.
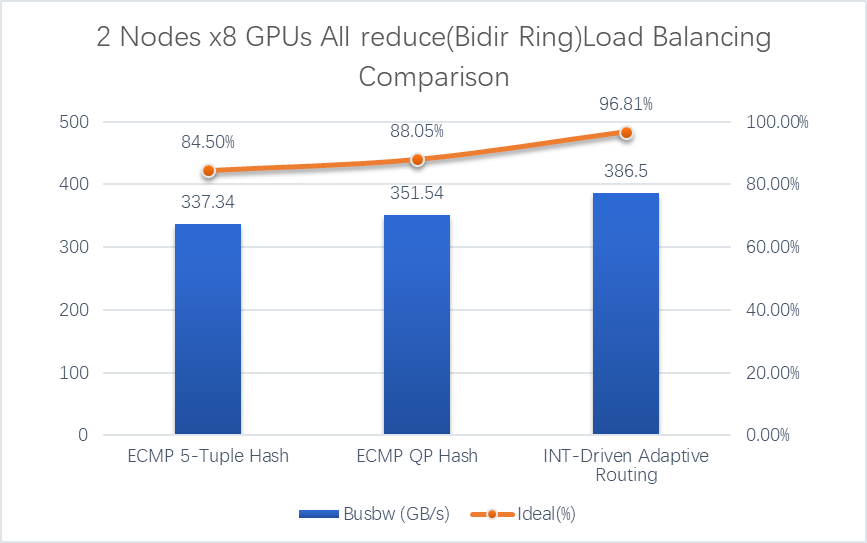
For technical directors, one set of numbers in the test report is particularly persuasive: in a 2-node × 8-GPU scenario, enabling ARS-supported INT-Based Routing increased All-Reduce bus bandwidth (BusBw) from 332.5 GB/s under ECMP QP Hash (QPs=8) to 386.5 GB/s, raising bandwidth utilization from 83.28% to 96.81%, an improvement of roughly 16%. For a typical LLaMA-39B training job, where communication accounts for about 55% of total time, this performance gain reduces the Job Completion Time (JCT) to 91.2% of its original value.
In other words, the effective performance of a single GPU improves by approximately 10%. Tasks that previously required 11 GPUs can now be completed with only 10, saving one GPU’s hardware cost and associated operational expenses. This data provides a highly persuasive metric for budget evaluations, clearly demonstrating potential hardware cost savings.
| Type | Algorithm | Busbw (GB/s) | Ideal (%) | Remark |
| All-Reduce | Bidir Ring | 332.5 | 83.28 | ECMP QP Hash QPs=8 |
| All-Reduce | Bidir Ring | 351.54 | 88.05 | ECMP QP Hash QPs=16 |

For AI research and development leads, the key factor in whether training tasks stall is how quickly data can be transmitted. With support from the Asterfusion CX864E-N ultra-low-latency switches, in a 2-node × 8-GPU All-Reduce training scenario, the Job Completion Time (JCT) drops to 91.2% of its original duration. This means project delivery timelines can be accelerated, eliminating the need to explain delays to business teams.
Ⅴ. Conclusion
Outstanding Spine-Leaf network performance depends not only on hardware capabilities but also on robust traffic scheduling and flow control mechanisms. Test results show that RoCEv2 ensures basic lossless transmission through PFC, implements soft rate control via ECN and DCQCN, and, when combined with ARS, achieves path-level load balancing—creating an open, flexible, and highly resilient flow control system.
The ARS technology in the Asterfusion CX864E-N switches maximizes the utilization of NCCL cluster hardware by splitting flows into flowlets and scheduling them in real time. Measured results of 97% bandwidth utilization and 2 μs low latency provide strong evidence that AI network optimization can effectively reduce costs while improving efficiency.




