Table of Contents
AIDC Network Classification
In modern AI compute clusters, networks are typically segmented into multiple planes based on the type of traffic they carry:
- Frontend Network: connects to the internet or storage systems and is responsible for loading training datasets.
- Backend Network (Compute Fabric / GPU Fabric): handles communication between GPUs and is dedicated to training and inference workloads.
- Storage Network: the backend storage fabric that provides access to large-scale data storage systems, enabling data access and retrieval between GPUs and high-performance storage devices.
- Management & Control Plane Network: serves as the “nervous system” of the cluster. It handles device monitoring, system provisioning, and routing/control protocols such as BGP and OSPF.
Note: In many small to medium-scale deployments, or in traditional Ethernet-based architectures, the frontend network, management network, and control plane network are often built on shared physical switching infrastructure. As a result, engineers frequently group them as “non-compute traffic” from an operational perspective. This is because these networks do not carry GPU-to-GPU parallel computation traffic (i.e., backend/fabric traffic), and they typically run standard TCP/IP protocols without strict ultra-low latency requirements. Therefore, they are often collectively referred to as the frontend/management network.
This article focuses on the comparison between frontend and backend networks, and further discusses how to design an efficient AI compute network architecture.
AI Frontend Network
The frontend network is the first layer connecting the AI data center (AI DC) to external systems. It primarily carries north–south traffic, enabling communication between external users and the data center. It is also responsible for storage access; however, frontend storage differs from backend storage in focus. Frontend storage is typically accessed through client/server models.
The frontend network is closer to a traditional data center network. It is based on TCP/IP technologies but imposes higher requirements on flexibility, manageability, and security.
Key Characteristics of the Frontend Network:
Service-oriented: Connects users, applications, and AI inference services.
Dynamic services: Continuously adapts to new applications, tenants, and service deployments.
Highly manageable: Supports automation, monitoring, and open interfaces such as NETCONF/YANG and REST APIs.
Low latency and high availability: Ensures responsive user experience and reliable service delivery.
Architecture
On the server side, the frontend network typically connects standard CPU-based servers. In AI inference scenarios, GPU servers may also be included in this layer. The typical topology follows:
Server → Top-of-Rack (ToR) → Spine, this represents a classic leaf–spine architecture used in Ethernet-based data center networks.
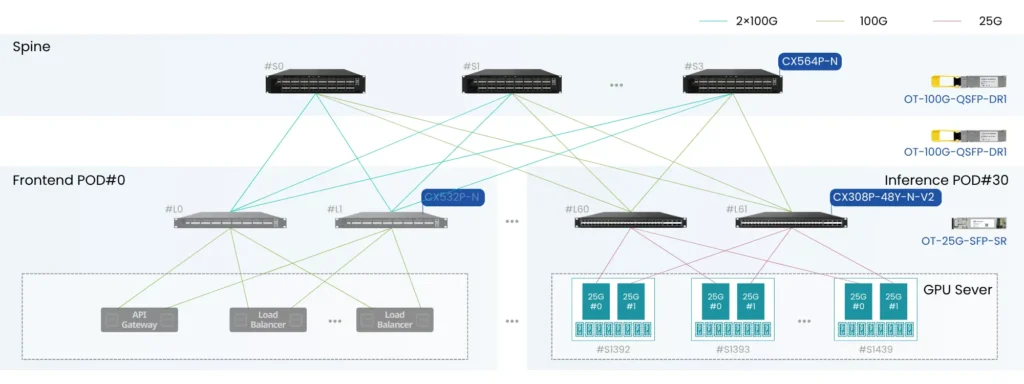
Key Principles and Performance Metrics of AI Frontend Network
The frontend network adopts a traditional leaf–spine architecture based on Ethernet switching, connecting CPU servers and storage arrays.
It primarily relies on north–south traffic patterns, supporting internet access, data retrieval, and AI inference request processing.
Key requirements for the frontend network include:
High Availability (HA):
Ensures service continuity with rapid failover between primary and disaster recovery sites. Convergence time is minimized using BFD + ECMP and LACP/M-LAG, enabling millisecond-level recovery.
Security:
Prevents external attacks, data leakage, and unauthorized access. Security domains are isolated using ACL policies, combined with VLAN/VXLAN-based segmentation. Regular security audits, traffic analysis, and anomaly detection are required.
Throughput and Bandwidth:
To handle internet traffic and AI inference requests, the spine layer must support high-concurrency traffic from multiple leaf switches. A near 1:1 oversubscription ratio is typically targeted to avoid congestion.
Scalability:
Must scale from tens to tens of thousands of servers and support multi–data center interconnect (DCI). Technologies such as GRE tunneling may be used.
Low Latency:
Frontend latency requirements are moderate compared to backend networks. Latency affects user experience—for example, in conversational AI systems, differences between 0.5 ms, 1 ms, or 2 ms are not perceptible to users. Even variations in the tens to hundreds of microseconds rarely become system bottlenecks. In contrast, backend latency directly impacts GPU synchronization efficiency, reducing cluster utilization and potentially increasing training costs significantly.
Manageability and Automation:
Because services change frequently, the network must support fast deployment and unified operations. Device management is typically implemented through NETCONF/YANG and REST APIs.
Network Isolation and Bandwidth Planning
Isolation design Frontend network traffic and frontend storage traffic may share the same physical infrastructure but are logically isolated. However, frontend and backend networks require strict physical separation.
Bandwidth planning Design must account for multiple traffic sources, including internet access, storage data movement, AI inference traffic, and future scalability requirements.
In summary, the frontend network is a service-oriented infrastructure layer responsible for external connectivity, data access, and operational management. It is built on a traditional leaf–spine architecture and optimized for north–south traffic. Its core design goals are high availability, security, throughput, and scalability. Typical implementations rely on high-end data center switches and emphasize technologies such as ECMP, BFD, MLAG, QoS, VXLAN, and automation capabilities.
AI Backend Network
The backend network is a dedicated communication fabric designed for GPU clusters (Compute Fabric). It carries protocols such as RDMA and RoCEv2. The primary traffic pattern is east–west traffic, including data exchange between GPUs within the data center and synchronization between storage nodes. It is responsible for AI training communication as well as intra-storage cluster replication and data consistency.
Although the backend network is also based on Ethernet, it relies on RDMA/RoCEv2 to build a lossless transport layer. As a result, it imposes extremely strict requirements on bandwidth, ultra-low latency, lossless delivery, and deterministic behavior.
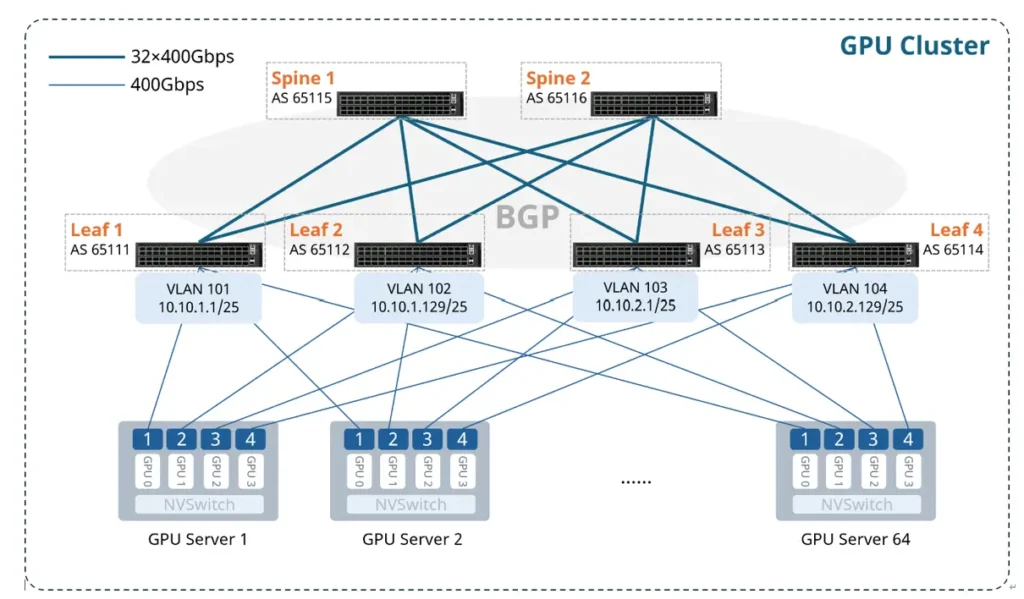
Key characteristics of the backend network:
Ultra-low latency: Minimizes GPU idle time and reduces synchronization delays, improving overall training efficiency.
Lossless Ethernet: Extremely sensitive to packet loss. Any packet drop triggers retransmission, increasing latency and potentially stalling the entire GPU cluster until the slowest node completes communication. Lossless behavior is achieved through mechanisms such as PFC, ECN, and DCB.
High bandwidth and scalability: As clusters scale to tens of thousands of GPUs, the network must provide high bidirectional bandwidth and horizontal scalability. Without this, GPUs become underutilized due to network bottlenecks.
Incast and elephant flow awareness:
- Incast: occurs when multiple senders transmit traffic to a single receiver simultaneously, creating a sudden traffic burst. This can overflow switch buffers and cause packet loss. A typical example is multiple GPUs sending results to a single aggregation node.
- Elephant flow: long-lived, high-bandwidth flows that consume a disproportionate share of network capacity. For example, transferring tens of GBs of model checkpoints.
To handle these behaviors, mechanisms such as ECN, adaptive routing, and in-network telemetry (INT) are typically required.
Architecture
The backend network is typically built on a Spine–Leaf (Clos) architecture, using Ethernet (RoCEv2) or InfiniBand switching technologies. It interconnects GPU clusters and storage nodes, enabling east–west traffic for distributed training and multi-replica synchronization within storage systems.
- Server layer: GPU servers serve as training nodes. Each server typically contains multiple GPUs (e.g., 8, 16, or 32). GPUs are interconnected via NVLink and PCIe within the server. Each GPU server connects to the network through NICs such as NVIDIA ConnectX, Ethernet NICs, or InfiniBand adapters.
- Leaf layer: Provides access connectivity for GPU servers (top-of-rack aggregation).
- Spine layer: Aggregates traffic from all leaf switches and provides multi-path interconnectivity across the fabric.
Key Principles and Performance Metrics of Backend Network
The backend network is designed with a strong focus on lossless transport. The goal is to build a non-blocking, low-latency, and highly scalable fabric that maximizes GPU utilization and eliminates network-induced bottlenecks. Any bottleneck directly increases training cost and slows down time-to-result.
Key metrics are centered on whether the network is slowing down GPU computation:
Lossless delivery The most critical metric. Packet loss rate must be near zero. Even a single lost packet can stall an entire training step due to synchronization dependencies.
Ultra-low latency Focuses on RTT and tail latency. In synchronous training, the slowest communication path determines overall step completion time, creating a classic “straggler effect”.
Congestion and traffic behavior Includes incast frequency, elephant flow ratio, queue depth, and microburst intensity. These indicators reflect whether the network is stable, controlled, and non-overloaded.
Bandwidth and throughput Evaluates link utilization, effective throughput versus theoretical bandwidth, and overall ToR/Spine uplink efficiency. The goal is to continuously feed GPUs with data and prevent compute stalls.
Scalability and load balancing Measures whether performance scales linearly with GPU cluster size. Key factors include ECMP hashing efficiency, traffic distribution fairness, and oversubscription design. The objective is to avoid hotspots and maintain system-wide balance as the cluster expands.
Backend Network Technology Options
Backend networks are typically implemented using either RoCEv2 over Ethernet or InfiniBand, depending on scale and operational requirements.
- RoCEv2 is based on Ethernet. It offers lower cost, open ecosystem, and deployment flexibility. However, it requires careful tuning of mechanisms such as PFC, ECN, and DCQCN to achieve lossless behavior, making operational complexity higher.
- InfiniBand provides native lossless transport and lower latency. It uses a more closed protocol stack but delivers higher stability. It is often preferred in very large-scale GPU clusters, including tens of thousands or even hundreds of thousands of GPUs.
Choosing between RoCEv2 and InfiniBand requires evaluating cluster scale, training workload characteristics, operational capabilities, cost considerations, ecosystem compatibility, and the required level of performance determinism.
Click here to learn about EasyRoCE Solution, which can be used to automate RoCE optimization and reduce manual configuration overhead.
Deep Comparison: AI Frontend Network vs. AI Backend Network
In high-performance AIDC environments, the frontend and backend networks operate under fundamentally different paradigms. The following table provides a comprehensive comparison of their operational characteristics.
| Dimension | Frontend Network (Frontend Network) | Backend Network (Backend Network) |
| Core Role | External service entry network | GPU compute communication fabric |
| Traffic Direction | North–South (external ↔ data center) | East–West (GPU ↔ GPU / storage ↔ storage) |
| Traffic Pattern | Stable + multi-service + bursty requests | Incast + elephant flows + microbursts |
| Primary Workloads | User access, AI inference, storage access, operations & management | Distributed training, gradient synchronization, storage replication |
| Architecture Model | Spine–Leaf (traditional data center design) | Spine–Leaf / Clos (AI-optimized fabric) |
| Core Challenges | Traffic bursts, security, multi-tenancy | Latency, jitter, lossless delivery |
| Protocol Stack | TCP/IP, VXLAN, ACL | RoCEv2 / InfiniBand + RDMA |
| Key Mechanisms | BFD, ECMP, LACP, M-LAG | PFC, ECN, DCQCN, adaptive routing (RoCEv2) |
| Latency Requirement | Moderate (user-experience level) | Ultra-low (GPU step-critical) |
| Packet Loss Tolerance | Tolerant to some packet loss | Near-zero tolerance (lossless required) |
| Bandwidth Model | Internet- and inference-oriented bandwidth | High-throughput GPU-to-GPU communication |
| Scalability | Multi-service, multi–data center (scale-up, scale-out, scale-across) | Large-scale GPU cluster (scale-up / scale-out ) |
| Security Focus | ACLs, isolation, multi-tenant security | Isolation and stability (security is secondary) |
| Hardware Focus | High-reliability data center switches | Low-latency, lossless-capable high-performance switches |
| Performance Bottleneck | Ingress bandwidth and short-flow handling | GPU utilization and training synchronization efficiency |
A key distinction is that frontend networks support Scale-Across deployments, while AI backend networks generally do not. Distributed AI training requires sub-microsecond GPU synchronization. Extending the backend fabric across geographically separated data centers introduces millisecond-scale network latency, making collective communication inefficient and significantly reducing training performance.
AIDC Backend Network Design
Why focus on the GPU backend network rather than the frontend network? A slower frontend network mainly affects user experience. In contrast, the backend compute fabric directly determines GPU utilization. It also defines the scalability limit of an AI cluster and offers much less tolerance for latency, congestion, and packet loss. As a result, backend network design and optimization have become the primary focus of AI infrastructure.
The backend fabric uses a Rail architecture to separate traffic patterns such as incast and microbursts across independent Rails. This distributes traffic more evenly, reduces transient congestion and packet loss, and minimizes GPU idle time caused by communication delays.
For small GPU clusters, the Rail-only architecture uses fixed Rail mappings to simplify communication paths. It reduces hardware cost while maintaining low latency through a deterministic network design. For larger clusters, the Rail-optimized architecture combines Rails, a two-tier Clos fabric, and multiple Groups to organize communication generated by distributed GPU training. This improves scalability and overall training efficiency.
This approach goes beyond switch optimization. It is a co-design of the GPU communication model and the network topology, addressing the communication explosion that occurs in large-scale distributed AI training.
For more details on Rail-only and Rail-optimized architectures, refer to the GPU Backend Network Design Guide.
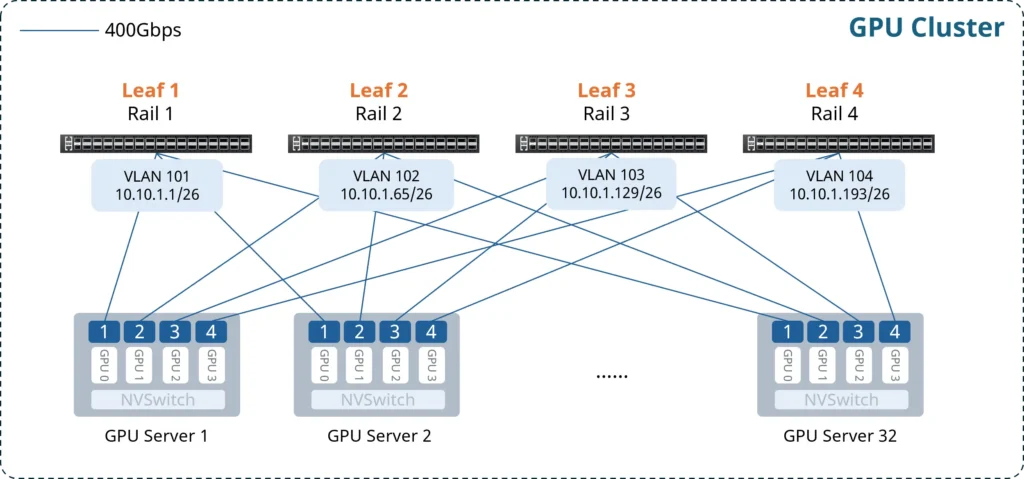
The following example illustrates the deployment of a small-scale AI compute backend network based on a cluster of 32 compute nodes. Each server is equipped with four GPUs, for a total of 128 GPUs. Four CX732Q-N switches are deployed as Leaf nodes. The key design principles are as follows:
- Deterministic Rail-only Connectivity: Each GPU is connected to a dedicated NIC, following the “NIC N to Leaf N” cabling rule. The fabric is physically divided into four independent Rail subnets, enabling single-hop communication between GPUs within the same Rail. This deterministic design provides predictable communication paths for distributed AI workloads.
- Flattened Network Topology: A single-tier Clos (Rail-only) architecture eliminates the traditional Spine layer. Fewer network tiers reduce switch and optical module requirements while eliminating the additional latency and jitter introduced by Spine forwarding. This architecture provides a cost-effective solution for AI clusters that require low latency and high communication efficiency.
- High-Performance Lossless Fabric:Easy RoCE is enabled on all Leaf switches to automatically deploy optimized lossless Ethernet configurations. PFC and ECN parameters are tuned to provide low-latency RDMA transport while minimizing congestion and packet loss, helping maintain high GPU utilization during distributed AI training.
- Non-blocking Network Design: The Rail-only fabric provides a 1:1 non-blocking architecture, ensuring that every server-facing port operates at line rate without oversubscription. Combined with deterministic forwarding paths, the architecture delivers consistent communication performance during distributed AI training.
To learn how to optimize RoCE lossless networking and traffic scheduling, including ECN/PFC thresholds, DSCP-to-queue mapping, and queue scheduling policies (SP/DWRR), refer to:
For medium-to-large-scale AI compute backend fabric design principles and deployment guidance, refer to:
For a step-by-step guide on how to automatically deploy an AI backend network, please refer to:
Conclusion
An AI data center network is fundamentally designed around traffic patterns and compute requirements. The frontend network carries north-south service traffic and client access, prioritizing high availability, security, and scalable service delivery. In contrast, the GPU backend fabric is the communication foundation for distributed AI training. It carries GPU-to-GPU east-west traffic and demands lossless transport, ultra-low latency, and deterministic high-bandwidth connectivity.
As GPU clusters scale from hundreds to thousands or even tens of thousands of GPUs, the network becomes more than an interconnect. It directly affects training efficiency, infrastructure scalability, and overall cost. The evolution from Rail-only to Rail-optimized architecture reflects different design priorities at different cluster sizes. Rail-only simplifies communication through fixed Rail mappings, reducing latency and deployment complexity. Rail-optimized extends this design with a Clos fabric and multiple Groups, enabling efficient communication and linear scalability for large GPU clusters.
Ultimately, designing an AI backend network is more than optimizing the switching infrastructure. It requires co-designing the GPU communication model with the network topology. By systematically tuning RoCE lossless networking, traffic scheduling, load balancing, and congestion control, operators can mitigate communication bottlenecks in distributed training, improve GPU utilization, and reduce the overall cost of AI training.
Request a demo or need assistance ?
Fill out the form, and we’ll reach out to you today !



