Table of Contents
AI infrastructure has reached a historic tipping point. As clusters scale toward 10,000—or even 100,000—GPUs, the old rules of networking simply don’t apply anymore. For years, InfiniBand was the undisputed gold standard, but in the face of massive LLM training, its “walled garden” ecosystem, supply chain risks, and eye-watering Total Cost of Ownership (TCO) are forcing developers to look elsewhere. This is why 2024 is being hailed as “Year One” for AI Ethernet. The industry has reached a consensus, we need a network that combines the open DNA of Ethernet with the lossless performance of proprietary protocols. With RoCEv2 rapidly capturing the 800G market, a high-efficiency, low-cost foundation for AI is finally taking shape. Leading this charge is Asterfusion—whose 400G/800G switches haven’t just timed the market perfectly; they’ve delivered a genuine breakthrough in end-to-end latency and automated operations.
The Invisible Accelerator: Why 400G/800G AI Switches Are Dominating the Data Center?

If you have your finger on the pulse of the AI industry, you’ve undoubtedly heard about the “compute crunch” and the massive demand for NVIDIA’s H100 or the new Blackwell chips. But while the spotlight stays on those high-priced GPUs, a quiet revolution in connectivity is unfolding behind the scenes. As clusters scale from a modest thousand GPUs to massive deployments of 100,000 nodes, the standard “network pipes” simply can’t keep up anymore. According to latest industry trends and research, 400G/800G switches are rapidly becoming the new backbone of AI compute power. Today, we’re breaking down the five core signals driving this transformation.
1. The Great Counterattack: Ethernet Moves to Center Stage
For the longest time, the AI backend was InfiniBand territory, prized for its “lossless” delivery. But according to the July 2025 Dell’Oro Group report, the tide is turning. In 2023, InfiniBand held 80% of the AI network market. By 2025, thanks to the maturity of RoCEv2 and the push from the Ultra Ethernet Consortium (UEC), Ethernet’s penetration in massive clusters has skyrocketed, beginning to outsell InfiniBand in 800G deployments. The Logic? Openness and Economics. Arista points out that for clusters exceeding 512 GPUs, Ethernet can slash TCO by 30% to 50%. For Tier-2 cloud providers and large enterprises, that is an offer they simply can’t refuse.
2. 800G is the New Floor—1.6T is Already on the Clock
IDC data shows a rate of iteration that is shocking even to veteran network engineers. In the first half of 2025, revenue for 800G switches surged by 220% quarter-over-quarter. 400G is now considered “entry-level,” while 800G has become a mandatory requirement for AI training backends. With NVIDIA’s Blackwell (GB200) shipping at scale, a single GPU’s bandwidth appetite has already crossed the 800Gbps mark. Cisco predicts that 1.6T (1600G) switches will enter initial test deployments as early as late 2026.
3. The Cooling Revolution: Keeping Networks from “Overheating”
Higher speeds usually mean terrifying levels of power consumption and heat. To prevent switches from becoming glorified space heaters, the industry is undergoing two hardware revolutions:
- LPO (Linear-drive Pluggable Optics): This technology has hit the mainstream in 2025. By removing the power-hungry DSP chips, it cuts power consumption by 25% and slashes latency by half. For AI training, where every microsecond of “tail latency” matters, this is a game-changer.
- CPO (Co-Packaged Optics): In ultra-scale racks, CPO is being piloted to package optical components directly with the silicon. The goal is simple: solve the thermal bottleneck to support even larger compute scales.
4. Autonomous Network Operations: Shifting from Manual Control to “Self-Driving” Infrastructure
As AI clusters scale past the 10,000-GPU milestone, the sheer complexity of network nodes has officially surpassed the limits of human configuration. In this new reality, the network operating system (NOS) is moving from the background to center stage, taking full command of fabric management. We are now seeing “Intelligent Agents” integrated into the OS to handle millisecond-level self-healing and congestion control. What used to take network experts weeks to tune (like ECN/PFC parameters) is now handled by smart algorithms, allowing Ethernet to deliver the same “silky smooth” lossless performance as InfiniBand.
5. Breaking the Monolith: Supply Chain Freedom
In the past, buying network gear was like buying a “pre-set menu”—you had to take the hardware and software from the same vendor. Meta’s OCP (Open Compute Project) has completely flipped the script.
SONiC Sovereignty: The open-source SONiC operating system is now the dominant force in the 400G/800G market. This means enterprises can choose their hardware without being locked into a single vendor’s ecosystem. at the same time, today’s cloud giants are playing it smart, sourcing chips from Broadcom, Marvell, and NVIDIA simultaneously. This multi-vendor strategy doesn’t just secure the supply chain; it forces competition and price drops, making 800G technology “democratized” for everyone.
AI Switch Market: Market Size, Speed, and Architecture Roadmap
| Key Metric | 2024 (Baseline) | 2025 (Current Forecast) | 2030 (Long-term Outlook) |
| AI Switch Market Size | ~$4.0 Billion | ~$5.2 Billion | ~$19.0 Billion |
| 800G Penetration (AI Networks) | < 10% | ~40% | > 85% |
| Compound Annual Growth Rate (CAGR) | — | 29.90% | — |
| Dominant Architecture | 400G / InfiniBand | 800G / RoCEv2 Ethernet | 1.6T / UEC Standard |
| Market Narrative | Proprietary Dominance | The Ethernet “Takeover” | Global Standardization |
Data Source: AI Data Center Switch Market – Global Outlook and Forecast 2024-2030 by Research and Markets.
Shattering the AI Compute Bottleneck: Why Choose Asterfusion 400G/800G High-Speed Switches?
In the era of Generative AI and LLM training, network performance is the single most critical factor determining the ROI of your compute power. Asterfusion’s 400G/800G series—purpose-built for AI/ML workloads—leverages an ultra-low-latency architecture and deep hardware-software synergy to deliver performance on an open Ethernet platform that rivals, and even surpasses, traditional proprietary networks.


“Low Latency in the DNA”: Marvell Teralynx and the 500ns Record

Asterfusion’s core series is built on the Marvell Teralynx 7 and Marvell Teralynx 10 architecture, shattering data transmission barriers at the physical layer.
- Ultra-Low 500ns E2E Latency: By optimizing chip-level cut-through forwarding, Asterfusion has successfully pushed end-to-end (E2E) latency down to a staggering 500 nanoseconds. This is a critical benchmark for eliminating the “wait time” during frequent gradient synchronizations in LLM training.
- Massive Bandwidth Throughput: With support for line-rate forwarding from 12.8 Tbps up to 51.2 Tbps per unit, combined with high-density 400G/800G ports, our switches ensure that even 10,000-node AI clusters remain lossless and low-latency under full-throttle traffic.
The Intelligent Hub: Enterprise SONiC with AI-Enhanced Features
Asterfusion deeply integrates an enterprise-grade SONiC operating system with specialized AI networking algorithms, evolving the network from mere “connectivity” to “intelligent orchestration.”
Enhanced AI features: By combining Packet Spraying, and Flowlet-based load balancing, INT-Driven Adaptive Routing,WCMP, Multicast Acceleration, PTP our SONiC implementation bypasses network hotspots in real-time. This ensures traffic is perfectly balanced across all available paths, effectively nuking network bottlenecks.

Lossless Fabric & Automated Deployment: The system features deep optimizations for RoCEv2, ECN, and PFC protocols. With our proprietary RoCE Easy Deploy technology, users can tune complex lossless networks with a “one-click” setup—shrinking deployment cycles from days to just minutes.
Openness & Observable Operations: Break free from vendor lock-in. Using advanced Telemetry, the system provides real-time awareness of network health and supports minute-level self-healing for AI traffic, ensuring 24/7 uptime for your compute clusters.
Benchmarking Performance: Asterfusion Ethernet vs. InfiniBand (IB)
Field data proves that while maintaining the inherent openness of Ethernet, Asterfusion has already overtaken traditional proprietary networks in key performance metrics:

| Key Metric | Asterfusion Performance | Technical Impact & Value |
| Min. Latency (E2E) | 500 ns | Reaches industry-leading levels, maximizing GPU communication efficiency and eliminating “idle time.” |
| P90 Latency Optimization | 20.4% Reduction | Drastically reduces “tail latency,” significantly accelerating the convergence speed of large model training. |
| Total Cost of Ownership (TCO) | 27.5% Savings | Delivers superior ROI for infrastructure and maintenance compared to expensive, proprietary InfiniBand (IB) ecosystems. |
| Job Completion Time (JCT) | Significantly Shortened | Boosts overall AI operational efficiency by effectively eliminating packet loss and network congestion. |
For more: RoCE Beats InfiniBand: Asterfusion 800G Switch Crushes It with 20% Faster TGR
400G or 800G? It’s More Than Just a Numbers Game
When building out an AI network, the million-dollar question is always: “Do I stick with 400G or make the jump to 800G?” While “double the bandwidth” sounds like an easy choice, the reality on the ground is far more nuanced. It’s a decision that depends on your GPU generation, the scale of your cluster, and how much “Job Completion Time” (JCT) you can afford to lose. Here’s how to find your sweet spot.
Match the Network to your “Compute Engine”
Your network bandwidth must be able to “feed the beast.” If your network can’t keep up with your GPUs, you’re essentially putting a supercar on a gravel road.
- The Case for 400G: If your cluster is built around NVIDIA A100s or early H100s, 400G is often the logical choice. It provides ample bandwidth for these chips, and the technology is incredibly mature and cost-effective.
- The Case for 800G: If you are eyeing the Blackwell (GB200) or scaling up H100/H200 deployments, 800G is no longer optional. The I/O capabilities of these next-gen chips have already crossed the 800Gbps threshold. To ensure the network isn’t the “ceiling” for your compute power, 800G is the way to go.
Cluster Scale: Two Layers vs. Three Layers
In AI training, latency is the enemy. Every extra “hop” your data takes between switches adds delay.
The Density Advantage: 800G switches offer higher port density (higher Radix). This means when you are building a massive cluster—say, 8,000 to 10,000 GPUs—you can often achieve a 2-tier architecture instead of 3. Fewer layers mean a vertical drop in end-to-end latency and fewer points of failure. However, if you’re building a smaller, localized pod for testing, the cost-to-performance ratio of 400G might better suit your current needs.
The 2027 Lens: Future-Proofing
As industry data suggests, by 2027, over 40% of AI backend networks will have moved to 800G.
If your infrastructure is intended to run for 3 years or more, deploying 800G today is a strategic move to protect your investment. It avoids a costly and disruptive network overhaul two years down the line when you inevitably move to even larger, more demanding models.
The Asterfusion Perspective:
The best network isn’t necessarily the most expensive one—it’s the one with the lowest latency and the most flexible path forward. Whether you choose 400G or 800G, Asterfusion provides a unified experience built on the Marvell Teralynx architecture. We ensure that even in a 400G environment, you can still achieve our record-breaking 500ns end-to-end latency. If you are looking for rock-solid stability and cost-efficiency for current-gen GPUs, our 400G series is the reliable workhorse. But if you are paving the way for massive, next-gen LLMs, our 800G series is the high-performance engine you need to unlock your full compute potential.
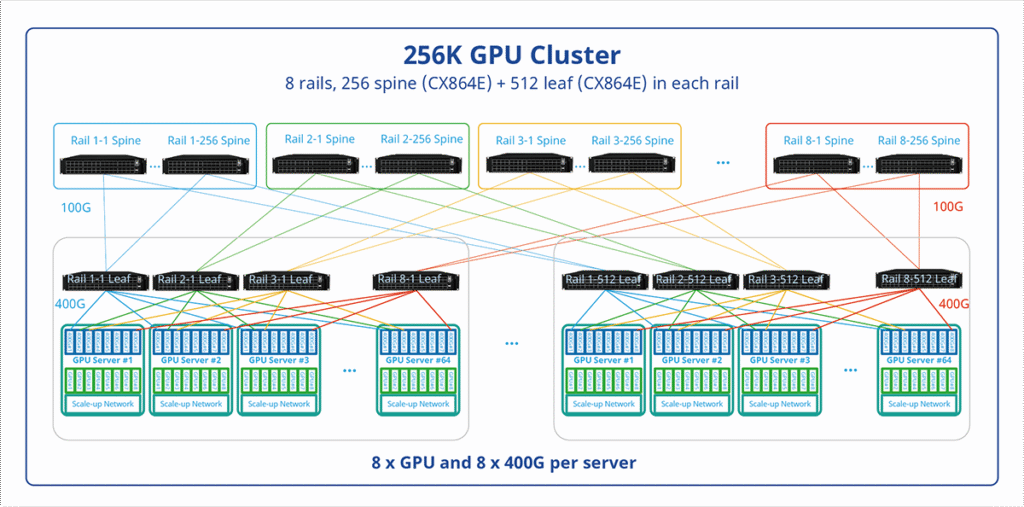
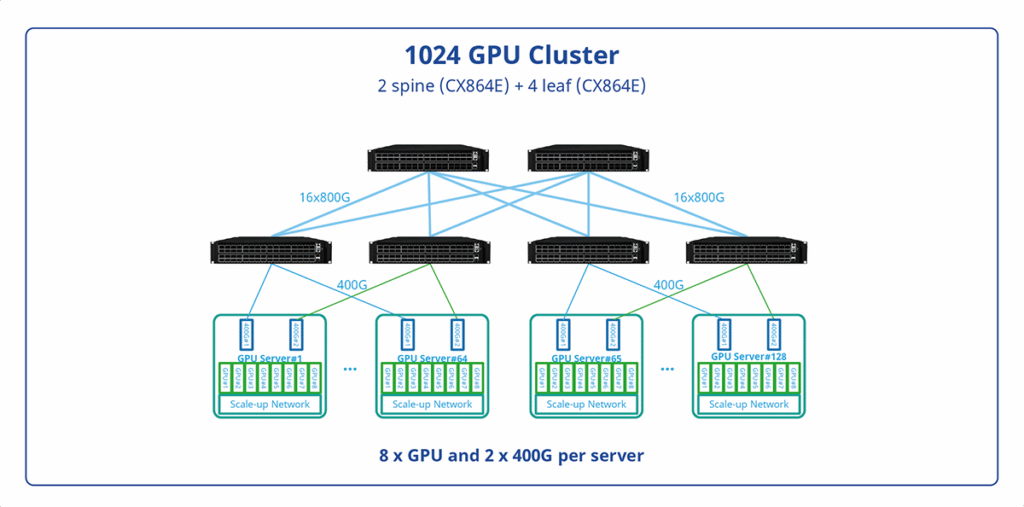
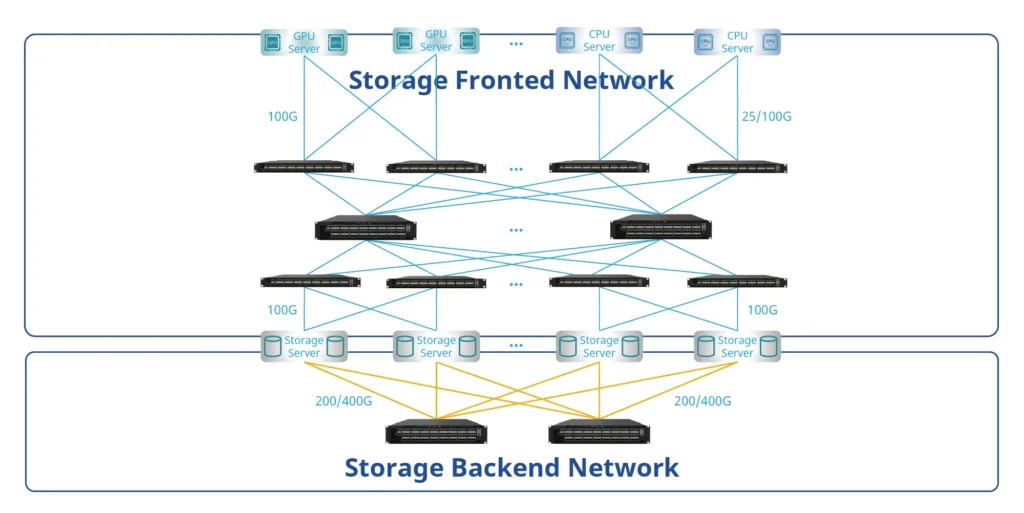
More about Asterfusion AI Network Topology: Visit https://cloudswit.ch/solution/ai-networking/
References & Industry Sources
- Dell’Oro Group: AI Networks for AI Workloads Report (2025 Edition)
- IDC: IDC’s Ethernet Switch Tracker Shows Double-Digit Increases Fueled by Datacenter Demand
- Arista Networks: The Sun Rises on Scale-Up Ethernet (OCP Summit 2025 Keynote)
- Research and Markets: AI Data Center Switch Market – Global Outlook & Forecast 2024-2030



