Table of Contents
Customer Background
Company M is a leading Chinese GPU chip designer focused on building a fully self-developed and controllable domestic AI infrastructure stack. With the rapid rise of large-scale model training and trillion-parameter multimodal workloads, the customer is constructing a next-generation hyperscale AI compute cluster, reaching over 8,000 GPUs in a single cluster.
In such large-scale deployments, network performance directly determines overall compute utilization efficiency. The customer’s requirements have evolved beyond simple “bandwidth scaling” and now focus on the deeper core of intelligent computing networks:
Customer Network Requirment
• Full InfiniBand replacement: Building a high-performance RoCEv2-based compute network on standard, open Ethernet infrastructure, with ultra-low latency and zero-loss characteristics.
• High communication efficiency: Large model training involves highly complex All-to-All collective communications, cross-rail traffic patterns, and hybrid parallelism. At certain stages, these workloads can trigger full-mesh traffic bursts across the network, requiring strong resilience against hash collisions and highly efficient adaptive load balancing mechanisms.
• Smooth evolution to 10K+ scale: The architecture must support seamless scaling from 8,000 GPUs to 10,000+ and even tens of thousands of GPUs, without degradation in oversubscription ratio or latency performance.
Why Asterfusion?
In AI training network scenarios, customers place extremely high demands on the network—not only bandwidth, but also latency, stability, and overall controllability. Especially in large-scale GPU clusters, network performance directly impacts training efficiency. After evaluating multiple solutions, the customer ultimately chose Asterfusion for several key reasons:
First, outstanding latency performance.
Based on high-performance Marvell switching silicon, the solution achieves end-to-end forwarding latency of around 500ns. In real-world large model testing, it demonstrates a highly cost-effective “InfiniBand alternative” capability, with key performance metrics narrowing the gap to InfiniBand (IB) to within 5%.
This breakthrough is critical for improving overall AIDC efficiency. In AI training scenarios with highly bursty elephant flows such as All-to-All and All-Reduce, it prevents sudden compute efficiency drops. In AI inference workloads with high-frequency small packets, it significantly improves token generation throughput by 27.5% and reduces P90 tail latency by 20.4%. Overall, the solution delivers a smooth experience comparable to proprietary closed-network architectures.
For more: RoCE Beats InfiniBand: Asterfusion 800G Switch Crushes It with 20% Faster TGR
Second, RoCEv2 vs. InfiniBand: Why RoCEv2 was the Final Choice
While InfiniBand offers low latency, it comes with a closed ecosystem and higher cost. Asterfusion, built on a RoCEv2-based Ethernet architecture, maintains Ethernet flexibility while achieving performance close to, or in some cases on par with, IB-level networks. This makes it highly attractive for customers. For more:
RoCE Or InfiniBand ?The Most Comprehensive Technical Comparison (Ⅰ)
RoCE Or InfiniBand ?The Most Comprehensive Technical Comparison (II
Third, strong alignment with open architecture principles.
The SONiC-based disaggregated design eliminates vendor lock-in, enabling greater flexibility for future scaling and upgrades.
For large-scale AI training and inference workloads, Asterfusion’s Enterprise SONiC has been deeply enhanced with key AI-native networking capabilities, including hardware-accelerated adaptive routing, high-precision INT (In-band Network Telemetry) for visibility, and fine-grained flowlet– and Packet Spray
This full suite of in-house lossless networking technologies not only eliminates hash collision issues but also gives customers strong confidence in deploying at hyperscale AIDC environments.
Overall, Asterfusion is not just delivering a high-performance networking solution—it provides a practical, production-ready balance between performance, cost, and openness.
AI Network Fabric Architecture Design (Compute + Storage Separation)
To ensure that compute and data workloads do not interfere with each other, this solution adopts a standard dual-plane architecture with strict separation between the compute network and the storage network.
Training Network: Rail-Optimized, Non-Blocking Dual-Layer Compute Fabric
The large-scale AI data center compute network (scale-out network) is built on a Rail-Optimized, dual-layer Spine-Leaf topology specifically designed for high-performance GPU clusters.
This is a non-blocking architecture designed to eliminate network bottlenecks. The network follows a standard two-tier Spine-Leaf design, consisting of 64 Spine switches and 128 Leaf switches.
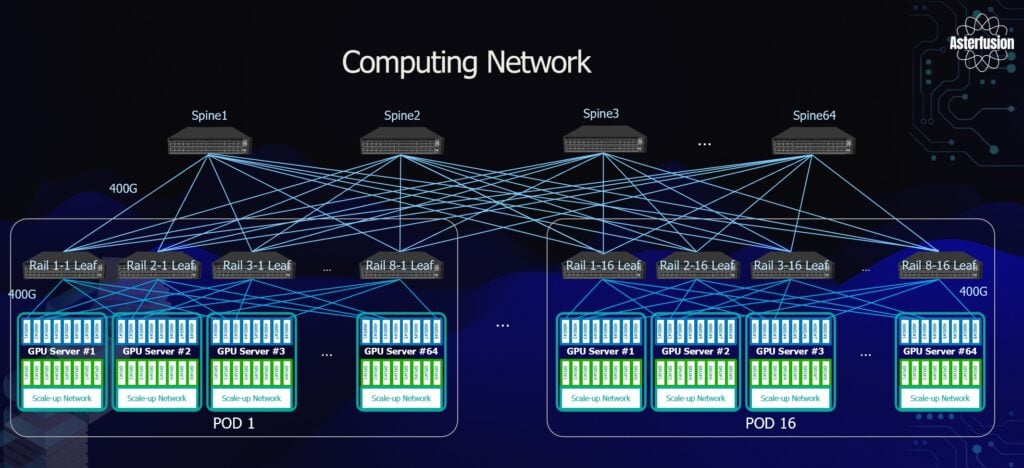
Strict 1:1 Non-Blocking Bandwidth Design
• Downlink (Leaf to servers): Each Leaf connects to 64 servers, with each link running at 400G, delivering a total downlink bandwidth of 25.6T per Leaf.
• Uplink (Leaf to Spine): Each Leaf connects to 64 Spine switches, also at 400G per link, resulting in a total uplink bandwidth of 25.6T per Leaf.
• The uplink and downlink bandwidth are fully symmetrical, eliminating any oversubscription and enabling true line-rate forwarding across the network.
8,192-GPU Scale Deployment
The network is designed around 16 PODs, with each POD containing 8 Leaf switches. The full cluster supports 1,024 GPU servers, totaling 8,192 MT-S5000 GPUs, approaching true hyperscale, near 10K-GPU deployment levels.
Rail-Only Traffic Isolation and Optimization
Through a Rail-based design, GPUs in the same position across all 1,024 servers (for example, GPU #1 in every server) are tightly bound to the same Rail Leaf group. During Rail-only communication, traffic is strictly confined within local rails, ensuring no cross-rail traffic occurs.
This significantly reduces the probability of multi-path hash collisions, effectively pushing the system toward the theoretical minimum interference level.
Dynamic Load Balancing and Microsecond-Level Failover
Instead of relying on traditional ECMP—which often fails under AI elephant-flow conditions—the architecture introduces Dynamic Load Balancing.
The switches continuously monitor queue depth and congestion across all 64 Spine links and dynamically distribute traffic based on real-time network conditions.
In the event of a Spine failure, dynamic routing protocols can reroute traffic within microseconds, seamlessly converging to the remaining 63 Spine switches. This prevents training interruptions and avoids costly checkpoint reload overhead in large-scale AI training workloads.
Storage Network (Asynchronous, Burst-Oriented Traffic)
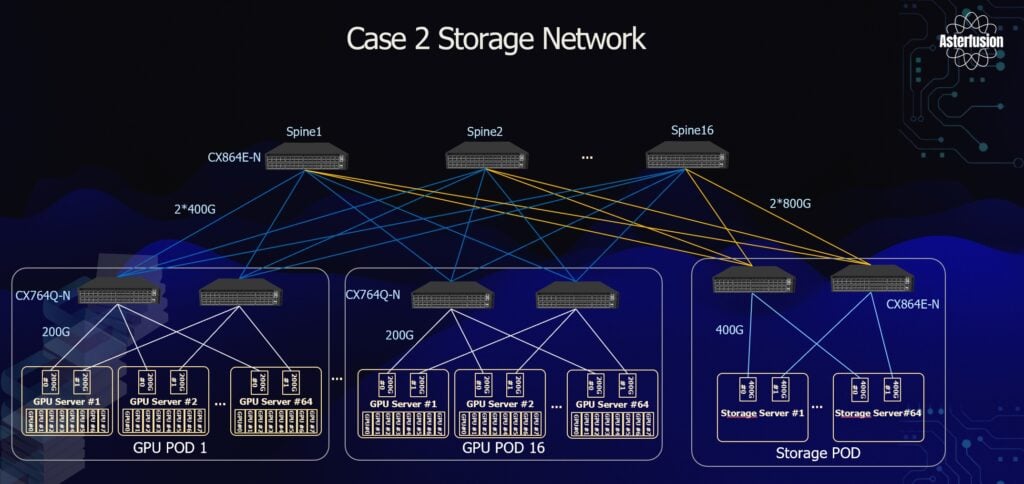
Unlike the compute network, which requires continuous high-bandwidth communication throughout training, the storage network mainly handles intermittent and highly bursty workloads such as periodic checkpoint writes and dataset loading.
Based on these characteristics, the design adopts a more cost-efficient and purpose-built asymmetric architecture built on a Spine-Leaf topology. The overall design is clearly divided into two parts: compute-side storage access and a dedicated storage backend.
Compute-Side Storage Access: GPU PODs (16 Pods)
This layer serves as the high-speed storage access network for AI compute nodes, enabling fast data read/write during training.
• Server configuration: Each GPU POD contains 64 GPU servers, and each server is equipped with a 2 × 200G NIC for storage traffic.
• Leaf layer: Each POD is equipped with 2 × CX764Q-N switches (64 × 400G ports). Downlinks use 400G breakout to 2 × 200G connections per server.
• Uplink design: Leaf switches connect to the Spine layer using aggregated uplinks of 2 × 400G per link.
Dedicated Storage Backend: Storage POD (1 Independent POD)
This layer serves as the centralized storage resource pool, providing the underlying data backbone for the entire cluster.
• Server configuration: The Storage POD consists of 64 storage servers, each equipped with 2 × 400G NICs to deliver higher per-node throughput.
• Leaf layer: This tier uses higher-spec CX864E-N switches (64 × 800G ports). Downlinks connect to storage servers at 400G.
• Uplink design: Since this layer aggregates the full cluster-wide storage throughput demand, uplinks from Leaf to Spine are doubled to 2 × 800G.
Core Aggregation Layer: Spine Switches
• The network uses 16 × CX864E-N switches (64 × 800G ports) as the Spine layer.
• These Spine switches interconnect 16 GPU PODs and 1 Storage POD, forming a fully non-blocking Clos-based storage fabric.
One-Sentence Summary: This architecture uses 16 GPU PODs to handle compute-side storage access, while a dedicated Storage POD provides centralized storage resources. Both are unified through a high-bandwidth, low-latency Clos storage fabric built on CX864E-N 800G Spine switches.

Conclusion
This design clearly demonstrates one key point: Asterfusion is not limited to “small or medium-scale AI networks.”In this project, starting from a base of 8,000+ GPUs, the architecture has already validated its capability to operate at true hyperscale, including:
• Large-scale horizontal scalability in a two-tier architecture
• Stable support for high-intensity All-to-All communication patterns
• Continuous operation under congestion and failure scenarios
In other words, this solution is not only capable of supporting large model training today, but is also designed to serve as a long-term network foundation for clusters scaling to 10K GPUs and beyond.
This is one of the key reasons the customer chose Asterfusion—not just to solve current challenges, but to future-proof their AI infrastructure for the next 5 years of compute growth.



