Table of Contents
With the explosive growth of AI large language models, high-performance computing (HPC), and NVMe-oF distributed storage, data center networks are rapidly transitioning to 400G. In core (spine) and high-density leaf-spine architectures, 32-port 400G switches delivering 12.8 Tbps of switching capacity have become the gold standard. However, even when two switches look identical on the outside—boasting the same 12.8T bandwidth and 32×400G port density—the underlying silicon dictates entirely different performance profiles and ideal deployment scenarios.
To help network architects navigate this, we are taking a closer look at Asterfusion’s two flagship 32×400G platforms, powered by two distinctly different Marvell ASICs: the Teralynx 7 (Asterfusion CX732Q-N) and the Marvell® Prestera® 98CX8500 (Asterfusion CX732Q-N-V2).

While both belong to the Marvell portfolio and run the same robust Enterprise SONiC operating system, their design philosophies couldn’t be more different. Here is how to choose between them.
The Sprint Champion: Teralynx 7 (Asterfusion CX732Q-N)
Design Philosophy: Speed is the Ultimate Weapon
The core design philosophy of Teralynx 7 is extreme low latency and maximum throughput. Rather than pursuing feature-heavy routing complexity, it focuses on what truly matters—delivering ultra-fast, deterministic performance for high-speed networks.

Key Strengths:
- Ultra-Low, Deterministic 500 ns’ Latency: Delivers approximately 500ns end-to-end latency, pushing the limits of physical performance. More importantly, latency remains highly consistent under load, which is critical for synchronization-sensitive workloads such as AI training and HPC.
- True Lossless Networking :Deeply optimized for RoCEv2, with strong dynamic microburst absorption capabilities, ensuring zero packet loss even under extreme throughput conditions.
- Flashlight™ Hardware Telemetry : Built-in In-band Network Telemetry (INT) provides nanosecond-level visibility into traffic flows without impacting forwarding performance, enabling real-time network observability.
- Advanced Buffering & Congestion Handling : Designed to effectively handle incast and microburst scenarios, making it an ideal fit for AI workloads and RDMA-based traffic patterns where congestion control is critical.
Teralynx 7’s Use Cases
Teralynx 7 is best suited for high-performance environments that are sensitive to latency and throughput, including:
- AI training networks (RoCE fabrics)
- HPC high-performance computing clusters
- High-performance cloud data centers
- Latency-sensitive east-west traffic scenarios
In these environments, latency and congestion directly impact job completion times and overall application performance. Teralynx 7’s ultra-low latency, lossless forwarding, and hardware-level telemetry can fully deliver value.
For information on how the Asterfusion CX532P-N can be used in AI inference networks, please refer to this case study: Case Study | Paratera × Asterfusion: Building a Future-Proof AI Inference Network
Teralynx 7’s Limitations
To achieve extreme forwarding speed and a streamlined architecture, Teralynx 7 reduces complex routing table capacity and does not support high-precision PTP (Precision Time Protocol). If your workloads require complex enterprise multi-tenant routing or nanosecond-level clock synchronization, Teralynx 7 may not fully meet the requirements and should be evaluated carefully.
The Versatile Midfielder: Falcon (Asterfusion CX732Q-N-V2)
Design Philosophy: “The All-Round Network Brain”
If Teralynx is a pure sprinter, the Falcon (Prestera 98CX8500) is a tactical powerhouse. It is designed for complex, multi-tenant environments where massive scale, precise timing, and deep traffic control are non-negotiable.
- Class C High-Precision PTP (10-ns Accuracy): This is Falcon’s absolute advantage over Teralynx. When paired with Asterfusion’s Enterprise SONiC, the Falcon silicon supports hardware-level PTP clock synchronization with an incredible 10-nanosecond accuracy. This makes it uniquely qualified for high-frequency trading, live broadcasting, and edge compute environments.
- Massive Table Capacity: Falcon dominates in scale. Its MAC tables (128K), ARP/ND entries, and IPv4/IPv6 routing prefixes are generally 3 to 4 times larger than those of Teralynx. For context, its IPv4 multicast routing supports a staggering 288K entries (vs. Teralynx’s 12K).
- Advanced Policy & Segmentation: With support for 4K VRFs and 10 Ingress/Egress ACL tables capable of holding thousands of rules, Falcon easily handles complex traffic scheduling, filtering, and strict multi-tenant isolation.
- SAFE (Storage-Aware Flow Engine): Falcon features an industry-exclusive ability to deeply identify RoCEv2-based RDMA flows, detect which storage nodes are congested, and enforce storage I/O SLAs directly at the network layer.
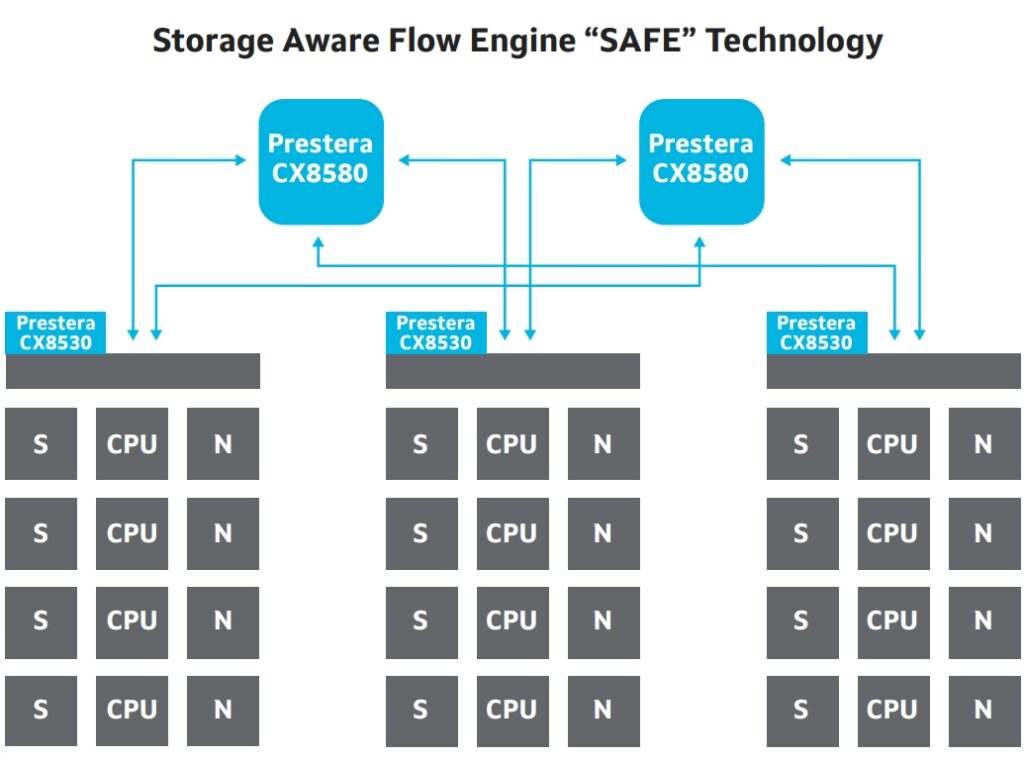
Falcon (Prestera 98CX8500)’s Ideal Use Cases:
Public and private cloud multi-tenant environments, enterprise aggregation or core networks, VMe‑oF disaggregated storage networks, hyper-converged infrastructure (HCI), live streaming and media platforms, edge data centers, and telecom-grade data centers requiring complex routing strategies.
Having compared the underlying switch chips, let’s now take a closer look at the hardware specifications of Asterfusion’s two 32×400G switches — the Marvell Teralynx CX732Q-N and the Marvell Falcon-based CX732Q-N-V2.


Below is a detailed comparison table that clearly shows that, although both switches feature 32×400G ports and run the Enterprise SONiC Data Center edition, the differences in chip capabilities lead to significant variations in features and ideal use cases.
Asterfusion 32*400G Switches Contrast Powered by Teralynx 7 & Falcon (Prestera 98CX8500)
| Group | Items | Product Series | |
| CX732Q-N-V2 Marvell Falcon | CX732Q-N Marvell Teralynx 7 | ||
| Device Capacity | Bandwidth | 12.8Tbps | 12.8Tbps |
| Packet Forwarding Rate | 5600Mpps | 7600Mpps | |
| Latency | ~1500ns | ~500ns | |
| Packet Buffer | 48MB | 70MB | |
| Table Size | MAC | 128K | 44K |
| L2MC | 16K | 14K | |
| ARP/ND | 92K/64K | 36K | |
| IPv4 Host | 288K | 96K | |
| IPv6 Host | 144K | 47K | |
| IPv4 Prefix | 288K | 72K | |
| IPv6 Prefix | 144K | 36K | |
| IPv4 Multicast Route | 288K | 12K | |
| VLAN | 4K | 4K | |
| VRF | 4K | 1K | |
| LAG | 128 Groups,64 Members | 256 Groups,128 Members | |
| ECMP | 4K Groups,256 Members | 4K Groups,256 Members | |
| IPv4/v6 ACL | 10 ingress/egress tables, 1500 ingress & 476 egress rules | 2 ingress & 1 egress tables, 256 ingress & 256 egress rules | |
| VXLAN Tunnel | 1K | 1K | |
| VXLAN Gateway | 4K | 4K | |
| STP | 64 | 64 | |
| Mirror | 6 | 24 | |
| System Capacity | BFD sessions | 512 | 128 |
| BFD capacity | 3x1ms | 3x300ms | |
| OSPF v2/v3 neighbors | 256 & 64 | 256 & 64 | |
| BGP/BGP4+ neighbors | 512 | 512 | |
| Secondary IPs | 16 | 16 | |
The Common Ground: Preload Asterfusion Enterprise SONiC
The hardware defines the ceiling, but the software unlocks the value. Both the CX732Q-N and CX732Q-N-V2 run Asterfusion Enterprise SONiC—a production-hardened distribution of the open-source SONiC.
Key Features:
- Virtualization: VXLAN, BGP EVPN, EVPN Multihoming
- Zero Packet Loss: RoCEv2, PFC/PFC Watchdog, ECN, QCN/DCQCN/DCTCP
- High Reliability: ECMP/Elastic Hash, MC-LAG, BFD for BGP & OSPF
- Automation & APIs: gNMI, REST, OpenConfig, Python & Ansible, ZTP, In-band Telemetry, SPAN/ERSPAN
Open Observability & Automation:
- Real-Time Monitoring: Integrated with Prometheus & Grafana, exporting CPU/memory, interface traffic/errors, latency, packet drops, RoCEv2 congestion metrics, and more.
- Automation & DevOps: Supports Zero-Touch Provisioning (ZTP), Python/Ansible automation, SPAN/ERSPAN, gNMI/OpenConfig for telemetry and control.
How to Choose Your right 400G swithes : Real-World Scenarios
When planning your 32×400G network, ask yourself one fundamental question: Is this network designed primarily to “feed GPUs,” or to “orchestrate massive storage and diverse enterprise services”?
1. AI & Machine Learning Compute Clusters ➔ Choose Teralynx 7
When training billion-parameter models, GPU-to-GPU communication (like All-Reduce operations) is ruthlessly sensitive to delay. Teralynx’s 500ns latency and massive 70MB buffer maximize AI cluster Job Completion Time (JCT). For pure GPU compute islands, this is the undisputed choice.
2. High-Frequency Trading (HFT) & Live Media ➔ Choose Falcon
These industries live and die by near-perfect timing. Because Teralynx lacks high-precision PTP, the Falcon switch is the only viable option here. Asterfusion’s implementation delivers Class C (10ns) PTP precision while retaining the flexibility of an open SONiC network.
3. NVMe-oF All-Flash Storage Networks ➔ Choose Falcon
In distributed storage, managing Incast congestion matters more than absolute baseline latency. Falcon’s SAFE technology intelligently throttles “rogue hosts,” smoothing out storage I/O and preventing jitter-induced performance cliffs.
4. Large Enterprise Core & Multi-Tenant Cloud Spine ➔ Choose Falcon
If your network acts as an edge gateway handling thousands of VPCs, mixed office traffic, ERP systems, and massive VXLAN tunnels, you need a “brain.” Falcon’s massive routing tables, deep packet inspection, and 4K VRF support provide the headroom and flexibility required to manage complex traffic orchestration.
Conclusion
At the end of the day, choosing between Teralynx 7 and Falcon isn’t about which switch is “better” — it’s about which one is better for your workload.
If your network is built to push the limits of performance — feeding GPUs, minimizing latency, and handling intense east-west traffic — Teralynx 7 delivers unmatched speed and deterministic behavior where every nanosecond counts.
On the other hand, if your environment demands scalability, rich routing capabilities, precise timing, and intelligent traffic control across complex, multi-tenant systems, Falcon provides the flexibility and depth needed to keep everything running smoothly.
The good news? You don’t have to compromise on software. With Asterfusion Enterprise SONiC running across both platforms, you get a consistent operational experience, open automation, and production-grade reliability — no matter which path you choose.
Ultimately, the smartest network designs aren’t built around hardware alone, but around a clear understanding of application demands. Choose the platform that aligns with your architecture, and your network will scale not just in bandwidth — but in efficiency, stability, and long-term value.



