Table of Contents
Storage Fundamentals
Data storage is the process of preserving data on physical media for future access and use.
Storage is not a single component. It is a vertical stack that spans from physical media at the bottom to application-facing interfaces at the top. Understanding this hierarchy is essential when analyzing storage networks in AI data center (AIDC) environments.
The storage stack can be broken down into the following six layers:
- Storage Media: The physical layer where data is stored, such as NAND flash, HDD platters, magnetic tape, optical discs, and DRAM cells. Examples include HDDs, SSDs, NVMe SSDs, and Storage-Class Memory (SCM).
- Storage Devices: Complete devices that integrate storage media, controllers, interfaces, power supplies, cooling systems, and firmware. Examples include SSDs, HDDs, tape drives, USB flash drives, and storage arrays.
- Storage Types: Define how data is organized and accessed. They include block storage (high performance), file storage (high compatibility), and object storage (high scalability).
- Storage Protocols: The communication protocols used between hosts and storage systems. Examples include NVMe-oF, S3, NFS, iSCSI, and NVMe/RoCE.
- Storage Systems: Complete storage platforms that combine devices, protocols, and management functions to provide reliable data services.
- Storage Architectures: Define how storage resources connect to compute nodes, including DAS, NAS, and SAN, as well as centralized and distributed storage deployments.
We can connect these layers together as follows: A piece of binary data is first organized as a file, block, or object. It is then accessed through a storage protocol such as NVMe-oF. The data is ultimately stored on physical media such as SSDs or HDDs, which are integrated into storage devices. Multiple storage devices and controllers are combined to build a storage system.
The storage system may use DAS, NAS, or SAN architectures, and can be deployed as either a centralized or distributed storage platform. These systems are interconnected through switches and networks, forming a storage network that delivers storage services to applications and workloads.
What Does a Storage Network Look Like in an AIDC?
In an AIDC, the storage network is typically a dedicated high-speed network fabric that carries traffic between compute nodes and storage systems. Its primary goals are high bandwidth, low latency, massive concurrency, scalability, and operational simplicity.
A Leaf-Spine architecture is commonly used. Storage nodes connect to leaf switches, which in turn connect to spine switches, creating a flat, low-latency, and highly scalable network fabric.
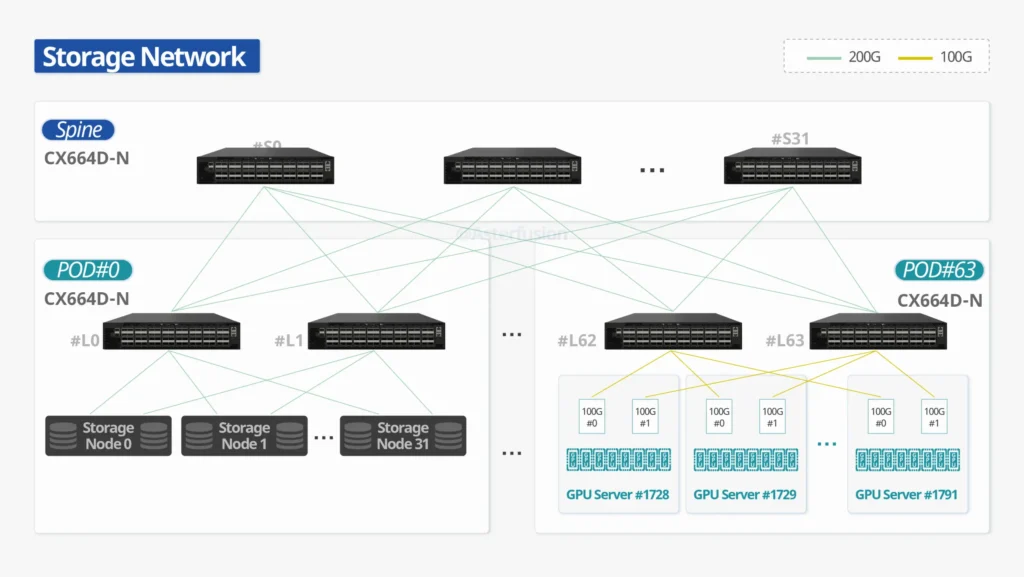
At the protocol layer, NVMe-oF (NVMe over Fabrics) extends NVMe access beyond locally attached devices to remote storage targets. When a compute node generates an I/O request, the request is transported across a high-speed fabric such as RoCE or InfiniBand to the remote storage node. This significantly improves training data access and checkpoint write performance, helping reduce the overall runtime of AI training jobs.
Learn more about AIDC frontend and backend networks, please refer to: The Fundamental Differences Between AI FrontEnd Networks and AI BackEnd Networks.
Types of Storage Networks in an AIDC
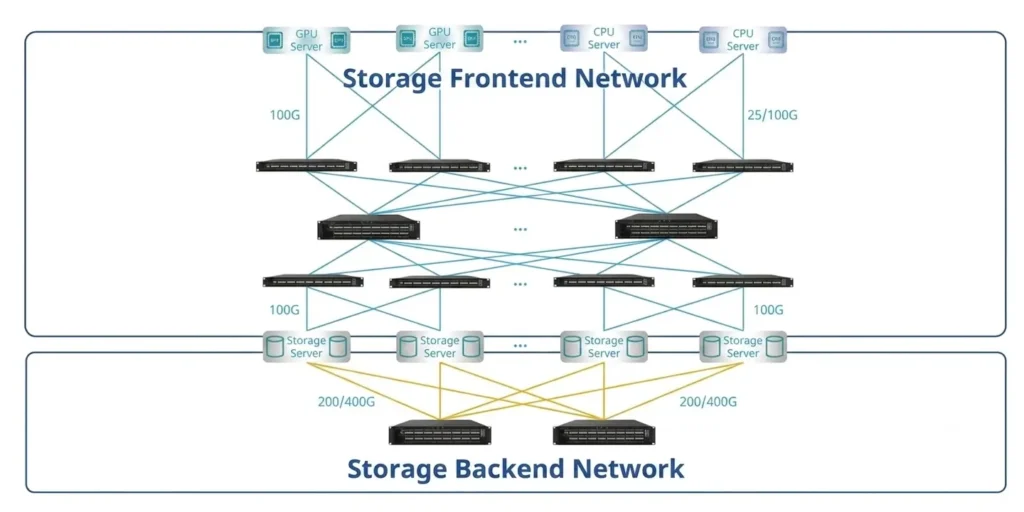
Storage networks in an AIDC are typically divided into two categories: the storage frontend network and the storage backend network.
Storage Frontend Network
The storage frontend network handles access between compute nodes and storage systems. Depending on scale and performance requirements, it may share the same physical infrastructure as the service network while using VLANs, VRFs, and QoS policies for logical isolation. In larger deployments, a dedicated storage fabric may be built to support hundreds of GPUs accessing training datasets simultaneously.
Typical workloads include training data reads, model checkpoint reads and writes, file sharing, and object storage access.
Storage Backend Network
The storage backend network is used for communication between storage nodes within the storage system. It is usually deployed as a dedicated network or designed with strong traffic isolation.
Typical traffic includes replica synchronization, erasure coding reconstruction, metadata synchronization, data rebalancing, recovery operations, data migration, and internal control or heartbeat traffic. The performance of this network directly affects data durability, recovery efficiency, and overall storage system performance.
Key Differences
In addition to being deployed on separate network fabrics or dedicated switching infrastructure, the primary difference lies in the workloads they carry.
- Storage Frontend Network: Focuses on application access performance, protocol compatibility, connection efficiency, and low latency. It primarily carries traffic between compute nodes or application servers and the storage system. In short, it focuses on who is accessing the storage.
- Storage Backend Network: Focuses on inter-node bandwidth, stability, scalability, and recovery efficiency. It is responsible for replica synchronization, reconstruction, and rebalancing traffic between storage nodes. In short, it focuses on how storage nodes collaborate with each other.
In practice, however, both the storage frontend network and the storage backend network typically serve the same storage cluster and the same set of storage nodes.
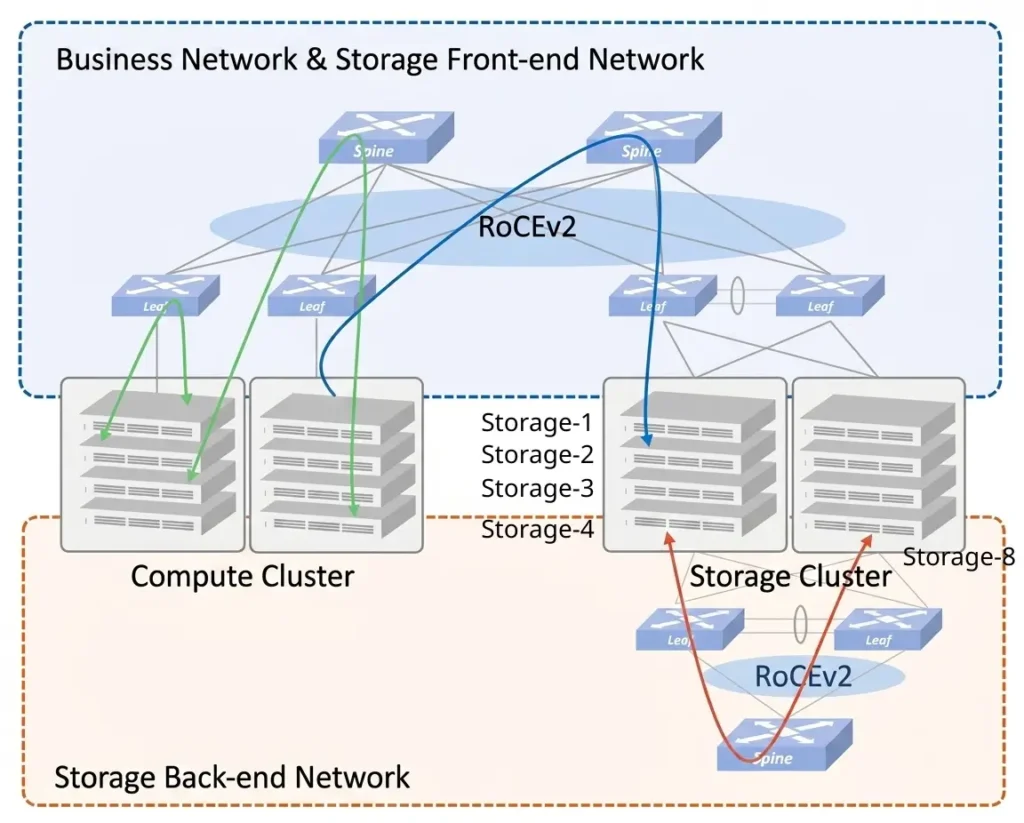
For example, consider a storage cluster consisting of eight storage servers, Storage-1 through Storage-8.
When a GPU cluster starts an AI training job, it typically accesses the storage system through the storage frontend network. Assume the training data is read from Storage-1. During training, checkpoints are periodically written back to Storage-1 through the same frontend network.
After Storage-1 receives the data written by the GPUs, it must satisfy the storage system’s data protection policy, such as replication or erasure coding (EC). To do this, Storage-1 synchronizes the data to other storage nodes, such as Storage-8, through the storage backend network.
In this example, frontend storage traffic flows between the GPU cluster and Storage-1, while backend storage traffic flows between Storage-1 and other storage nodes as part of data replication or protection operations.
In practice, many distributed storage systems provide separate frontend and backend network interfaces on each storage node. The frontend interface connects to GPU servers, compute nodes, or application systems. The backend interface is dedicated to internal storage traffic, including replica synchronization, erasure coding reconstruction, recovery, and data rebalancing.
As a result, the same storage node participates in both frontend and backend storage traffic. For example, Storage-1 communicates with GPUs through its frontend interface while simultaneously communicating with Storage-8 and other storage nodes through its backend interface.
What Device Is Required for a Storage Network?
A storage network in an AIDC is typically built from three main components: leaf switches, spine switches, and a network observability/operations platform.
Leaf Layer
At the leaf layer, switches such as CX664D-N provide high-density server and storage connectivity. It offers 64 × 200G QSFP56 ports and supports flexible breakout modes, including 2 × 100G per 200G port.
This design fits high-density GPU clusters and NVMe storage nodes. For general workloads, 100G links can be used to balance cost and compatibility. For high-performance compute or storage nodes, 200G links are deployed to remove bandwidth bottlenecks and reduce congestion under heavy traffic.
Spine Layer
The spine layer is built with high-performance backbone switches such as CX664D-N or CX732Q-N, which is based on the Marvell Teralynx 7 chipset.
CX732Q-N provides up to 12.8 Tbps switching capacity and ultra-low latency performance. It supports 32 × 400G QSFP-DD ports with flexible breakout options (100G/200G).
With a large 70 MB packet buffer and support for 9216-byte jumbo frames, it helps build a stable and lossless RoCEv2 fabric. This is critical for AI workloads that require predictable high-bandwidth transport for storage and compute traffic.
AI Network Operations Platform
This AIDC Operations Platform provides topology visualization, centralized configuration management, and integrated alerting. It simplifies the operational complexity of AI storage networks, helps identify bottlenecks, and enables proactive network monitoring. The goal is to ensure high availability and stable performance for large-scale AI workloads.
Storage Network Deployment Performance: Benchmark Results
To validate the effectiveness of the proposed storage network architecture under AI workloads, tests were conducted in an environment based on CX-532P-N low-latency RoCE switches and NVIDIA ConnectX-5 NICs. The benchmark includes 4KB and 8KB random read/write workloads, with InfiniBand (SB7700) used as the reference baseline.
Key Test Results
Low-latency optimization: In direct connectivity tests between a single compute node and a storage node, the CX-532P-N-based RoCE fabric demonstrates strong latency performance. Compared to the InfiniBand setup, read latency is reduced by up to 6.3%, while write latency is reduced by up to 10.1%.
IOPS and throughput improvement: Under multi-stream concurrent stress tests (two compute nodes accessing two storage nodes), the architecture achieves improved performance through an efficient lossless transport mechanism. Read IOPS increases by 6.1%, while write IOPS improves by up to 10.5%.
Lossless Storage Network Advantages
Full-stack protocol compatibility: The solution is built on RoCEv2 and integrates PFC, ECN, and DCBX flow control mechanisms to ensure lossless transmission. It is fully compatible with high-performance storage protocols such as NVMe-oF, Ceph, Lustre, and BeeGFS.
Intelligent congestion avoidance: With INT-based in-band telemetry and adaptive routing mechanisms, the network can detect link utilization in real time and dynamically avoid congested paths. This reduces tail latency in storage workloads and improves data flow stability during AI training and model checkpointing.
Summary
By upgrading traditional InfiniBand-based designs to a high-performance RoCEv2 storage fabric built on modern Ethernet switches, the system achieves measurable IOPS gains while maintaining lower latency. Combined with broad protocol compatibility and intelligent traffic steering, this approach provides a scalable and efficient foundation for AI storage infrastructure and high-performance storage pools.
FAQ
Q1: Why do we need to separate frontend and backend storage networks for AI training?
In AIDC, GPU training is highly sensitive to storage performance.
The frontend storage network handles GPU access to storage, focusing on low-latency, high-concurrency data reads and writes such as training data and checkpoint operations.
The backend storage network handles internal storage traffic such as replication, EC rebuild, and heartbeat between storage nodes.
If both are mixed, backend bursts (e.g., EC rebuild) can congest the network and introduce long-tail latency, slowing down GPU training jobs.
Q2: Why is RoCEv2 more complex than NVMe/TCP?
RoCEv2 relies on a lossless Ethernet fabric, requiring tight coordination of PFC, ECN, and DCBX across all devices.
Any misconfiguration can cause congestion spreading, pause storms, or performance collapse.
NVMe/TCP is simpler to deploy and more tolerant of network behavior, making it a better choice when extreme low latency is not required.
Q3: How to detect performance bottlenecks in AI storage networks?
Average bandwidth is not enough. Microbursts can still cause severe latency.
Key signals:
Queue depth / buffer occupancy
PFC pause frame counters
INT telemetry for per-hop congestion visibility
Q4: InfiniBand or RoCEv2 for AI storage networks?
There is no absolute “best” choice. InfiniBand offers native lossless behavior and strong performance for large-scale HPC. RoCEv2 runs on Ethernet, with better ecosystem compatibility and lower operational cost.
In most Ethernet-based AI infrastructures, RoCEv2 is the more practical choice.



