Table of Contents
The networking industry is rapidly accelerating into the 1.6T port era. Driven by the explosive growth of AI training clusters and next-generation compute networks, bandwidth evolution is no longer a linear progression, but an exponential leap. 400G is now the standard, 800G is being deployed at scale, and 1.6T is imminent. At Asterfusion, we remain rooted in engineering pragmatism, actively advancing our next-generation 1.6T open switching platform powered by Marvell® Teralynx® T100 and Enterprise SONiC, dedicated to delivering the optimal high-performance, cost-effective solution for the AI era.
But before we dive into any new 1.6T technologies, we must first confront a brutal reality: this is not merely a simple speed upgrade. It is a critical, system-level inflection point where physical laws are putting a “chokehold” on the architecture.
In the 400G and 800G eras, traditional pluggable optics could still survive on patchwork fixes like squeezing power and tweaking thermals. In fact, foundational overhauls like CPO (Co-Packaged Optics) were already being explored by pioneers during the 800G cycle. But because traditional architectures could still hold the line, the industry wasn’t forced into taking drastic survival measures.


However, as we cross into the 1.6T (102.4T switch silicon) era, these traditional engineering optimizations are are beginning to show severe systemic strain. The core trigger behind this underlying crisis is the most overlooked variable in the entire link—the SerDes (Serializer/Deserializer).
As extremely high-frequency electrical signals hit an absolute dead end in power consumption and signal integrity, the emerging optical interconnect architectures that have been quietly wrestling behind the scenes—Co-Packaged Optics (CPO), Near-Packaged Optics (NPO), and Linear Pluggable Optics (LPO)—are finally being thrust onto the main stage to dictate the industry’s trajectory.
These three radically different paths essentially represent life-or-death trade-offs among performance, power efficiency, supply chain security, and operational risk. The core question is no longer “how to achieve 1.6T,” but rather, “in the face of the actual commercial bill and absolute physical limits, which one is the truly deployable solution?”
Physical Limits in the 1.6T Era: SerDes Breakdown and Runaway System Costs
At its core, 1.6T pushes the single-lane SerDes rate to the absolute limits of 200G PAM4. At these extreme frequencies, the electrical signals traversing the PCB become incredibly fragile:
- The Absurd Power Penalty: To salvage these signals—which constantly threaten to simply dissipate into heat along the PCB traces—traditional modules have no choice but to brute-force the problem by cramming in increasingly heavy, power-hungry DSPs (Digital Signal Processors) for on-the-fly signal recovery. This effectively turns the optical modules into miniature space heaters, sending single-port power consumption skyrocketing to 25W–30W.
- The Collapse of Physical Space: Hand in hand with this power surge is a front panel that is neither big enough to fit everything nor porous enough to cool it. The sheer density of bulky modules and thermal cages essentially chokes the switch’s front panel into an impenetrable wall of heat.
- The Fatal Hidden Flaw in Stability: The absolute worst enemy of an AI training network is link flap or jitter. Under 200G conditions, signal margins are razor-thin; even the slightest physical flaw can trigger link retraining, instantly plunging a ten-thousand-GPU cluster into a state of agonizingly expensive idle waiting.
Confronted with this physical dead end, the theoretical antidote offered by the industry is: CPO (Co-Packaged Optics).
What is CPO( Co-Packaged Optics)?
At its core, a 1.6T CPO (Co-Packaged Optics) switch removes the optical modules from the front panel and integrates them directly onto the same substrate as the switching ASIC. 1.6T refers to the single-port transmission rate of 1.6 Terabits per second (typically achieved via eight 200G SerDes lanes).
In plain terms: You rip the “optical modules” off the front panel, scrap the pluggable form factor, and weld them directly onto the switching chip.
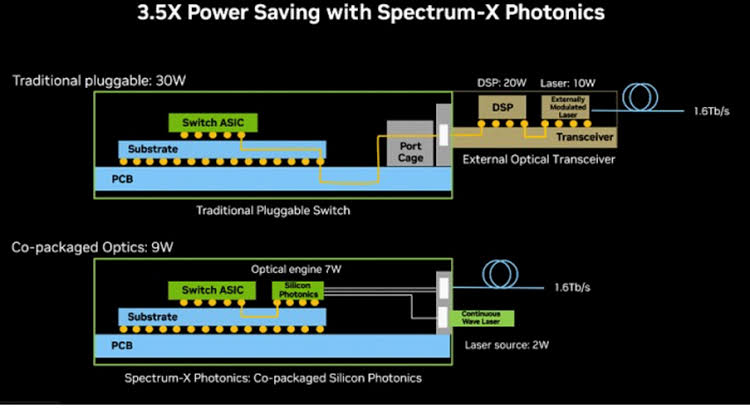
Power consumption comparison between traditional pluggable optics and CPO architectures. Source: APNIC Blog
The Upside: A Perfect Theoretical Logic
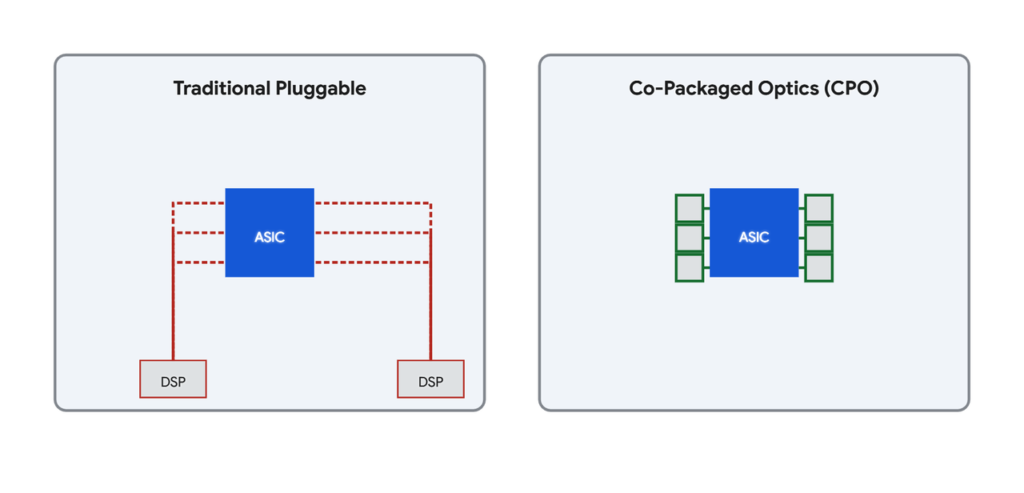
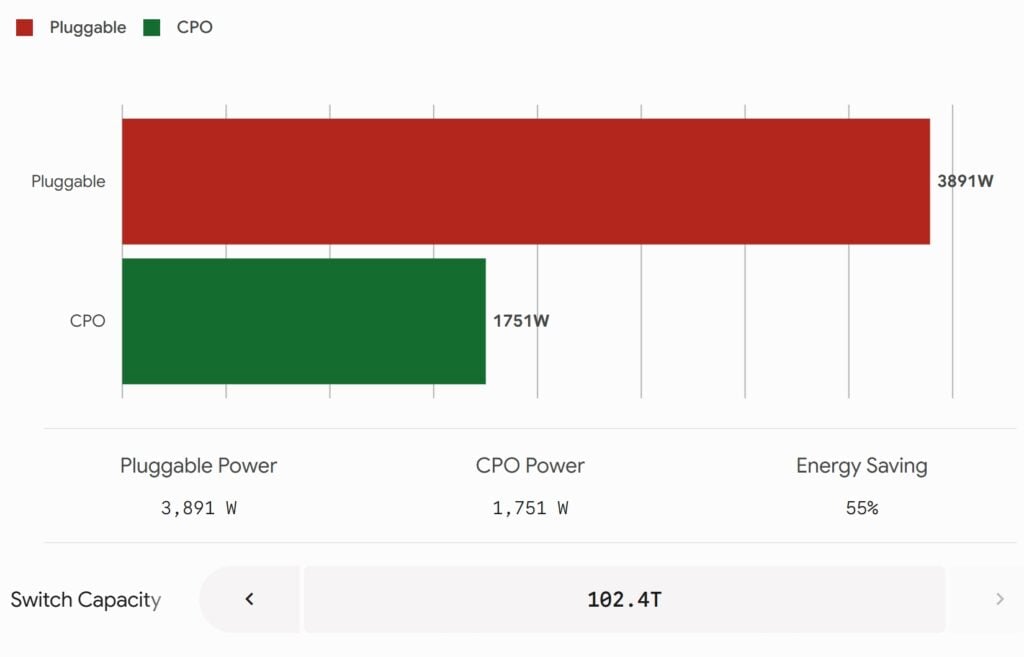
The theory is flawless: since electrical signals are bound to fail if forced to run long distances across a PCB, why not compress that distance from ten-plus centimeters down to just a few millimeters? Under this ideal vision, CPO solves a host of problems:
- SerDes lanes no longer suffer from board-level insertion loss
- The need for heavy DSP processing plummets (or vanishes entirely)
- Power consumption is slashed by 70%
- and the front panel is liberated, becoming nothing more than a pure fiber-optic interface.
The Downside: Engineering Reality and the Cold Hard Bill
However, technology cannot be judged by laboratory limits alone; it must be measured against the cold, hard bill of real-world deployment.
We must recognize that CPO is not an upgrade to traditional optics—it is an ultimate gamble that stakes the customer’s operational bottom line and supply chain security.
- It breaks the supply chain and kills hot-swapping: It forces a “shotgun wedding” between astronomically expensive switching ASICs and short-lived optical components.
- A “death sentence” for the ASIC: Given the currently abysmal yields in advanced packaging, if a single optical channel fails, the entire high-value core chip is effectively collateral damage. Operational costs shift from a one-second hot-swap to powering down the unit, dismantling it, and returning it to the factory.
- The Physical Hegemony of Silicon Giants: It grants silicon giants (like NVIDIA and Broadcom) absolute physical hegemony, stripping equipment manufacturers and customers of any flexibility or choice.
While CPO offers clear theoretical advantages in power efficiency, its fundamentally disruptive approach—breaking traditional supply chains and eliminating pluggability—comes at a significant cost. By tightly coupling expensive switching ASICs with optical components that have inherently shorter lifespans, CPO introduces substantial risks in both operations and supply chain management. Under current manufacturing yield constraints, this becomes a high-stakes trade-off, placing considerable pressure on the entire ecosystem.
When the cost of a radical architectural shift outweighs its immediate benefits, the market tends to favor more pragmatic solutions. As a result, “middle-ground” approaches have emerged as the practical choices in the 1.6T era.
The first is Linear Pluggable Optics (LPO), which preserves the operational simplicity of traditional pluggable modules while reducing power consumption by removing the DSP.
The second is Near-Packaged Optics (NPO), representing a pragmatic engineering compromise. By retaining most of the power and signal integrity benefits of co-packaged approaches, while keeping optical and electrical components physically separable, NPO maintains supply chain flexibility and serviceability. In essence, it avoids forcing customers to absorb the risks associated with immature packaging yields.
What is LPO (Linear Pluggable Optics)?
Linear Pluggable Optics (LPO) is an evolution of the traditional pluggable optical module, designed to slash power consumption and streamline system complexity in high-speed scenarios such as 800G and 1.6T.
In traditional pluggable optics, a DSP (Digital Signal Processor) is typically integrated to handle signal conditioning, equalization, and retiming. While the DSP effectively boosts signal quality, it also introduces substantial power consumption, latency, and cost overhead.
LPO adopts a radically different design philosophy: it completely eliminates the DSP, offloading the heavy lifting of signal integrity to the host side (including the switching ASIC and the PCB board-level design). This approach creates a “linear” electrical path between the switching chip and the optical engine—which is exactly where it gets its name.
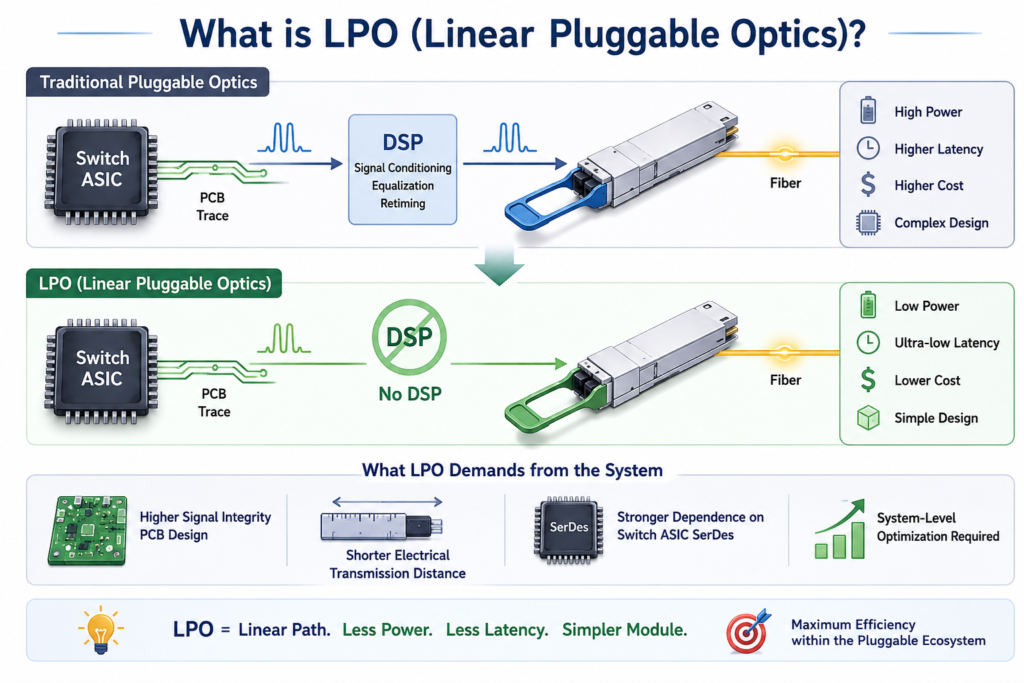
By removing the DSP, LPO modules deliver:
- Significantly lower power consumption
- Ultra-low latency
- A highly simplified module design
However, this architecture simultaneously places much more stringent demands on the overall system:
- Higher signal integrity requirements for PCB design
- Shorter electrical transmission distances
- Heavier reliance on the performance and capabilities of the switching chip’s SerDes
In essence, LPO is not a subversive architectural revolution, but a pragmatic optimization within the existing pluggable ecosystem—trading off a degree of signal robustness to gain maximum efficiency and rapid deployability.
What is NPO (Near-Packaged Optics)?
NPO (Near-Packaged Optics) is the practical “middle ground” architecture that sits precisely between traditional pluggable optics and CPO (Co-Packaged Optics). It was engineered to solve the high-frequency signal attenuation of long PCB traces without falling into the packaging and maintenance traps of CPO.
The Design Philosophy: “Close, But Not Married”
In a CPO architecture, the optical engines are welded directly onto the same substrate as the switching ASIC. NPO, however, takes a step back.
It removes the optical engines from the front panel and places them on the host PCB, immediately adjacent to the switching chip substrate—typically within a distance of just a few centimeters. The connection between the ASIC and the optical engine is routed through ultra-low-loss board traces or high-performance miniature cables.

Why the Industry Secretly Loves NPO: The Practical Compromise
By keeping the optical engines “near” rather than “co-packaged,” NPO delivers a critical commercial balance:
- Drastic Power and Loss Reductions: Because the electrical path is compressed from 10+ centimeters down to just a few, signal attenuation plummets. This vastly relaxes the workload on both the SerDes and the DSP, unlocking massive power savings that approach the efficiency of CPO.
- The Lifeline of “Opto-Electrical Separation”: This is NPO’s ultimate trump card. Because the optical engines and the high price tag ASIC are not permanently bound to the same substrate, they remain decoupled. If an optical channel fails, you can hot-swap or replace that specific NPO module on the board without rendering the multi-thousand-dollar switching chip collateral damage.
- Preserving the Supply Chain Ecosystem: NPO allows switch OEMs and optical component manufacturers to maintain their traditional boundaries. It prevents silicon giants from monopolizing the entire packaging ecosystem, keeping the supply chain flexible, open, and high-yielding.
In Short: If CPO is an idealistic, radical revolution that forces a high-risk “shotgun wedding” between chips and optics, NPO is the engineer’s sober dose of reality. It gives the industry 80% of CPO’s performance benefits while fiercely protecting the operational bottom line: maintainability , yield, and supply chain freedom.
Comparasion of CPO /NPO/LPO
| Dimension | CPO (Co-Packaged Optics) | NPO (Near-Packaged Optics) | LPO (Linear Pluggable Optics) |
| Optical Engine Placement | Co-packaged with switching ASIC | Placed near the ASIC (on-board) | Front-panel pluggable |
| Electrical Link Length | Shortest | Short | Longest |
| Power Consumption | Lowest | Moderate | Higher |
| Signal Integrity | Best | Good | Most Challenging |
| System Complexity | Highest | Moderate | Lowest |
| Serviceability | Lowest (non-pluggable) | Moderate | Best |
| Deployment Maturity | Early stage | Transitional stage | Most mature |
| Cost Structure | High (advanced packaging) | Medium | More controllable |
| Typical Use Cases | Future large-scale AI / HPC | High-performance DC (transition phase) | Mainstream / cost-sensitive deployments |
Who Will Dominate the 1.6T Era?
When compute nodes step outside the chassis and copper cables hit their physical limits, optical interconnects become the only cure. Yet, as of mid-2026, if you tear away the flamboyant technical whitepapers and look at actual datacenter procurement lists and engineering baseboards, the cold, hard bill of the optical battlefield is brutally clear.
The 99% Mainstream: Pluggables and LPO for Today’s Reality
Customers’ GPUs are burning cash by the second. They simply cannot afford to wait for a hypothetical future, nor do they want to shoulder the risks of restructuring switch physical form factors or disrupting established operational habits. Consequently, LPO (Linear Drive Pluggable Optics) is experiencing an incredibly fierce breakout. The reasons are straightforward:
- Lowest Risk: No system-level architectural overhaul required.
- Operational Continuity: Seamlessly compatible with existing datacenter maintenance frameworks.
- Immediate Efficiency: Yields short-term power optimization primarily by stripping out the DSP.
At its core, LPO remains tied to traditional 1.6T switch architectures, merely trading the removal of the DSP for a drop in power consumption. It is by no means subversive. Yet, by being “plug-and-play, low-risk, and immediately deliverable,” it has become the undisputed cash cow of the moment. In the 2026–2027 window, LPO stands as the most realistic and scalable choice. Currently, the 1.6T switches rolling out from major ODMs—such as Accton, Celestica, and Alpha Networks—are all built entirely on traditional architectures.
Of course, the traditional pluggable approach is also a core part of Asterfusion’s 1.6T switch R&D roadmap.
The Industry’s Little Secret: Hyping CPO while Secretly Shipping NPO
If you carefully dismantle the equipment of major vendors claiming to have “fully mastered CPO,” you will uncover an open secret whispered across the industry: To spin compelling stories for capital markets, everyone talks about CPO; yet in actual engineering delivery, their systems honestly retreat to NPO (Near-Packaged Optics).
The reality behind this is purely practical—true CPO packaging yields are outright nightmarish. To protect multi-thousand-dollar switching ASICs from being dragged down by short-lived optical components (where a single failed optical lane ruins the entire chip), engineers have drawn a strict “line of demarcation” on the substrate, leaving those last few centimeters unmerged. NPO defends the baseline of “opto-electrical separation”—if an optical engine fails, it can be individually replaced. NPO tackles all the dirty work of engineering deployment and supply chain decoupling, while leaving the marketing spotlight entirely to CPO’s slide decks. NPO is not a compromise; it is the commercial bottom line that engineers fiercely defend.
The 1% Vertical Extremes vs. “Futures Marketing”: Navigating CPO Under Different Ecosystem Philosophies
Has the era of true, all-optical CPO (Co-Packaged Optics) genuinely arrived? Looking objectively at mid-2026, CPO has admittedly completed its leap from “concept” to “system-level engineering realization.” However, scratching beneath the surface of technical whitepapers reveals that it remains a “long-term architectural endgame” used to freeze future budgets, rather than a plug-and-play solution ready for mass deployment by 99% of market players today.
Peering into the absolute pinnacle of 102.4T switching silicon, the industry’s top titans have split into two fundamentally distinct technology faiths based on their commercial DNA:
1. NVIDIA’s Vertical Integration and Absolute Performance Limits
As the vanguard of global AI compute, NVIDIA’s core pursuit is always extreme, system-level cluster performance. To suppress overall power consumption and latency in massive AI training workloads, it is aggressively driving CPO restructuring across its next-generation flagship networking portfolios (Spectrum-6 for Ethernet and Quantum-X for InfiniBand).
This represents a classic “full-stack vertical integration” philosophy: anchoring the optical interfaces with its own high-efficiency chip ecosystem at the wafer packaging level. Through this tight physical bonding, NVIDIA can squeeze the last ounce of performance dividend out of every photon for top-tier AI factories. However, this bleeding-edge technology demands exceptionally high standards for packaging yields, chassis thermal design, and field serviceability. As NVIDIA’s official roadmap indicates, this architecture is currently entering only the “Early Adoption” phase with a handful of hyper-scale customers. Note the precise wording: “Early Adoption,” not “Mass Deployment.” This means that even by late 2026, NVIDIA’s CPO switches will remain in an early stage of small-scale trials and reliability verification among a select few.
2. Broadcom and Marvell: Open Standards and the Multi-Path Pragmatism
In contrast to the vertical integration school of thought, public-market merchant silicon giants like Broadcom and Marvell focus on serving a standardized, industry-wide ecosystem. Consequently, in the 102.4T era, they lean toward a pragmatic, multi-path strategy:
- Broadcom: Its CPO platform (Tomahawk 6 – Davisson) showcases tier-one packaging prowess, utilizing sixteen 6.4T silicon optical engines to achieve a stunning 70% reduction in optical interconnect power. Yet, Broadcom is acutely aware of the diverse demands of the open market. Because a single failed optical channel can condemn an entire premium ASIC, Broadcom simultaneously offers the standard Tomahawk 6—a pure electrical ASIC supporting traditional pluggables and LPO—firmly handing the architectural choice back to system OEMs.
- Marvell: As a staunch proponent of open AI datacenter infrastructure, Marvell takes this flexibility to the extreme with its Teralynx T100 102.4 Tbps AI switching silicon. Engineered on a 3nm process, the T100 natively supports CPO evolution at the architectural level while maintaining a rational equilibrium for real-world engineering delivery. It empowers switch manufacturers to freely choose between pushing for the absolute performance of CPO or retaining the high-yield, easily serviceable profiles of NPO, LPO, or traditional pluggables, depending on their supply chain readiness and actual ROI.
This non-coercive, highly inclusive architecture embodies the exact core values championed by the Enterprise SONiC open networking ecosystem. This is precisely why Asterfusion firmly stands by building our next-generation 1.6T open switching platform on the Marvell T100. We refuse to chase a singular, isolated performance myth. Instead, we leverage a robust, reliable silicon foundation to help 99% of mainstream users find the safest, most pragmatic equilibrium between absolute physical limits and real-world commercial balance sheets.
Asterfusion’s 1.6T Dilemma—A Tale of Two Fronts, A Rational Playbook Balancing Business and Physics
Confronted with the system-level inflection point of the 1.6T era, Asterfusion will neither blindly chase the allure of a flawless “physical future” nor shut its eyes to the looming “physical wall.” Staying firmly rooted in engineering pragmatism, we are actively forging ahead along two highly purposeful switch technology roadmaps:
Front 1: Defending the Commercial Base — Pluggable & LPO Ecosystem
Powered by the Marvell T100 silicon and Enterprise SONiC open networking ecosystem, we are driving our next-generation 1.6T open switching platform at full throttle. This solution anchors itself to today’s most mature industrial supply chain, delivering plug-and-play deployment flexibility and the highest operational fault tolerance. Throughout the upcoming datacenter compute marathon of 2027, this route will remain the absolute backbone helping 99% of our customers protect their ROI balance sheets and win the immediate battles of compute capacity.
Front 2: Anticipating the Physical Endgame — CPO/CPX Evolution
We have never denied that CPO represents the ultimate all-optical endgame. In the 1.6T phase, it remains throttled by real-world chronic ailments—including nightmarish packaging yields, disastrous maintenance overheads, and ecosystem closedness—rendering large-scale mass production unfeasible in the short term. However, looking at the long-term horizon, as compute networks barrel toward 3.2T, 6.4T ports, and even grander physical thresholds, the power walls and signal integrity limitations of traditional pluggables will inevitably face a total meltdown. To this end, Asterfusion’s R&D and validation efforts in CPO have never paused; we are proactively layouting the groundwork for pluggable-like (CPX) co-packaged technologies that prioritize field-serviceability and ecosystem compatibility.
Asterfusion’s stance is unequivocal: We refuse to join the silicon giants in closed games aimed at crushing the supply chain, nor do we rely on slide decks to market immature futures. We empower our customers to quench their immediate compute thirst with the most pragmatic pluggable and LPO switches, while simultaneously paving the next-generation runway for future hyper-scale AI datacenters with cutting-edge CPO technical capabilities. This is the true, pragmatic power of open networking.
References:
- Broadcom Unveils 102.4 Tbps Davisson CPO Switch for AI Clusters (https://convergedigest.com/broadcom-unveils-102-4-tbps-davisson-cpo-switch-for-ai-clusters/)
- Scaling AI Factories with Co-Packaged Optics for Better Power Efficiency – NVIDIA Technical Blog (https://developer.nvidia.com/blog/scaling-ai-factories-with-co-packaged-optics-for-better-power-efficiency/)
- How open ecosystems will advance CPO adoption ( https://www.ciena.com/insights/blog/2026/how-open-ecosystems-advance-cpo-adoption)
- Marvell Announces Availability of Industry’s First 102.4 Tbps Switch Purpose-Built for AI and Cloud Data Center Infrastructure (https://www.marvell.com/company/newsroom/marvell-announces-102-4-tbps-ai-cloud-data-center-switch.html)
- Broadcom Delivers the Future of AI Infrastructure with End-to-End AI Networking Solutions at 2025 OCP Global Summi ( https://investors.broadcom.com/news-releases/news-release-details/broadcom-delivers-future-ai-infrastructure-end-end-ai-networking)



