In AI, HPC, and other high-performance, lossless networks, people often discuss RoCE (RDMA over Converged Ethernet) and InfiniBand (IB). We have detailed the differences and relationships between these two protocol stacks(see: Comparison and Analysis of RoCE vs. IB Protocol Stacks). RoCE adapts the mature InfiniBand transport layer and RDMA to Ethernet and IP networks.
InfiniBand was the first protocol to support RDMA. It has a head start and a mature tech stack. It has a full suite of specialized hardware and software. It delivers very low-latency transmission. However, its reliance on a single vendor often leads to a higher Total Cost of Ownership (TCO).
On the other hand, RoCEv2 is cheaper and more interoperable. So, it is better for large-scale deployments. For instance, xAI’s AI cluster in Memphis, USA, has over 100,000 cards. It uses a 400GbE Ethernet-based, lossless, high-speed network.
Can Open Network Switch Replace InfiniBand?
Quoting Amazon Senior Principal Engineer Brian Barret, the reasons why AWS abandoned the InfiniBand solution are clear:
“A dedicated InfiniBand network cluster is like an isolated island in a vast ocean. It meets the needs for resource scheduling, sharing, and other elastic deployments.”
The industry is shifting to standard openness and multi-vendor compatibility. Open networks like SONiC have been deployed in large cloud environments. This trend is hard to ignore. This raises an important question: Can open networks using RoCE be a viable alternative to InfiniBand in high-performance AI/HPC scenarios?
Moreover, could the flexibility of open architectures provide broader benefits to data center operators? For instance, could they simplify the complex RoCE network setup and tuning? Could they enhance operational and diagnostic capabilities? And could they offer even more possibilities?……
Test Background
We tested SONiC switches (RoCE) against InfiniBand (IB) in three scenarios: AI training, HPC, and distributed storage. The results are presented with precision, and the testing methods are briefly outlined to provide valuable insights for our readers.
- AI Intelligent Computing Scenario: E2E forwarding tests, NCCL-TEST, and large model training network tests
- HPC Scenario: E2E forwarding performance, MPI, Linpack, and HPC applications (WRF, LAMMPS, VASP)
- Distributed Storage: FIO tool used to measure read and write performance under stress
The RoCE switch tested is the Asterfusion CX-N series, which features an ultra-low latency hardware platform and is equipped with the enterprise-grade SONiC distribution AsterNOS. All ports support RoCEv2 natively and are paired with the EasyRoCE Toolkit.
CX-N series model specifications are shown in the following table:
| Model type | interface |
| CX864E-N | 64 x 800GE OSFP,2 x 10GE SFP+ |
| CX732Q-N | 32 x 400GE QSFP-DD, 2 x 10GE SFP+ |
| CX664D-N | 64 x 200GE QSFP56, 2 x 10GE SFP+ |
| CX564P-N | 64 x 100GE QSFP28, 2 x 10GE SFP+ |
| CX532P-N | 32 x 100GE QSFP28, 2 x 10GE SFP+ |
(10G interface can be used exclusively as INT)
The network operating system architecture installed on the switch:
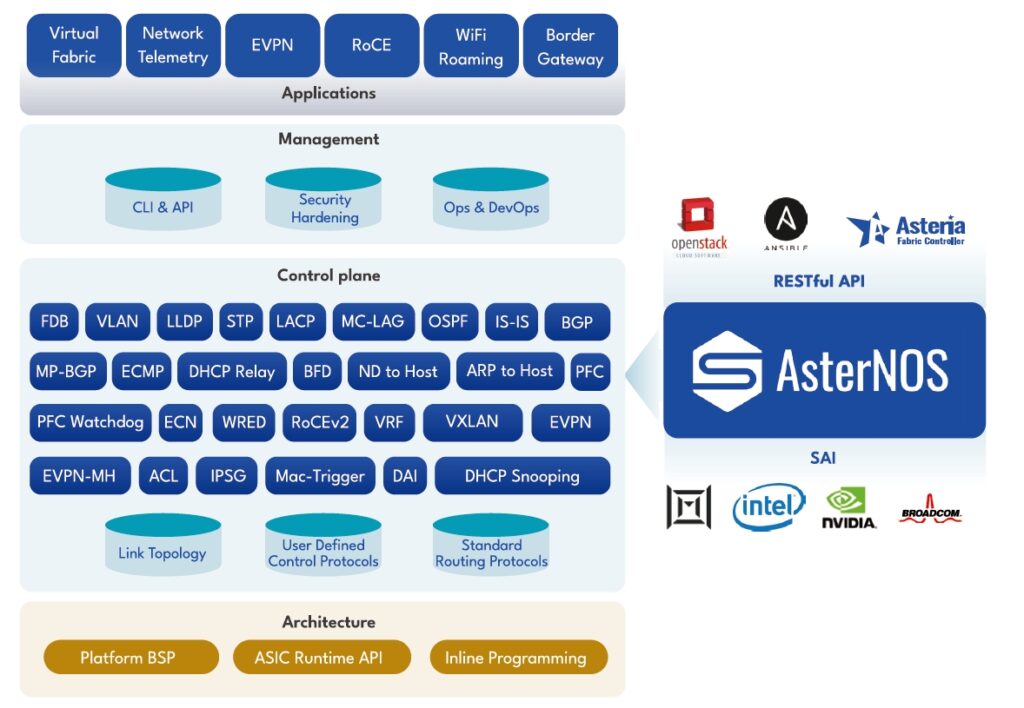
Test Conclusion
The open architecture Asterfusion CX-N series switch (RoCE) provides end-to-end performance that matches InfiniBand (IB) switches, and in some cases, even outperforms them.
AI Intelligent Computing Scenario
- The E2E forwarding bandwidth matches the NIC’s max rate. The latency is as low as 560ns on a single machine.
- Running the NCCL-test (Ring algorithm) with two machines and 16 cards, the maximum total bus bandwidth measured through the two tested switches is nearly identical to the IB switch (around 195GBps). The bandwidth usage matches the NIC direct connection. It reached the max speed for server scale-out.
- With an optimized topology, the training time for Llama2-7B (2048 token length) on two machines with 16 cards matches the results from both NIC direct connection and IB networking.
HPC Scenario
- The E2E latency performance is almost identical to that of the IB switch, with differences staying within the nanosecond range.
- In the MPI benchmark test, E2E performance closely matches the IB switch, with latency differences also in the nanosecond range.
- Linpack efficiency is nearly the same as when using an IB switch of the same specification, with differences of around 0.2%.
- When running WRF, LAMMPS, and VASP applications in parallel within an HPC cluster, the average time to complete the same computational tasks using the RoCE switch is comparable to that of the IB switch, with differences ranging from 0.5% to 3%.


Distributed Storage Scenario
The Input/Output Operations Per Second(IOPS) of the distributed storage system using a RoCE network is comparable to that of the same-spec InfiniBand network, and under certain conditions, it even outperforms InfiniBand.

Appendix: Testing Method and Main Steps
AI Intelligent Computing Scenario
The network is set up according to the topology shown below. The Mellanox MLNX_OFED driver is installed on the Server machines, and upon installation, the IB testing tool suite (including tools such as ib_read_lat, ib_send_lat, ib_write_lat) is automatically included. Using this tool suite, Server 1 acts as the sender, while Server 0 serves as the receiver. The tests measure the forwarding link bandwidth, latency, and packet loss through the switches.
- The switch port forwarding latency is calculated as the difference between the total communication latency and the NIC direct connection forwarding latency.
- NCCL-test is run using the mpirun command with all_reduce_perf. The measured bus bandwidth increases with the data volume, and the maximum value observed is used as the test result.

Enabling GPU Direct RDMA
Load the nv_peer_mem kernel module.
root@gpu:~# modprobe nvidia_peermem
root@gpu:~# lsmod |grep nvidiaManual compilation method:
root@gpu:~# git clone https://github.com/Mellanox/nv_peer_memory.git
root@gpu:~# cd nv_peer_memory && make
root@gpu:~# cp nv_peer_mem.ko \
/lib/modules/$(uname -r)/kernel/drivers/video
root@gpu:~# depmod -a
root@gpu:~# modprobe nv_peer_memACSCtl check
Disable the PCIe ACS configuration, not disabling it will cause the NCCL performance limit bandwidth to not reach the expected value.
root@gpu:~# lspci -vvv|grep ACSCtl:|grep SrvValid+
# If there is no output, the configuration is normal. If there is output, execute the following script
root@gpu:~# cat ACSCtl.sh
for pdev in `lspci -vvv|grep -E "^[a-f]|^[0-9]|ACSCtl" \
|grep ACSCtl -B1|grep -E "^[a-f]|^[0-9]"|awk '{print $1}'`
do
setpci -s $pdev ECAP_ACS+06.w=0000
doneRDMA-related configuration
root@gpu5:~# cat rdma.sh
#!/bin/bash
for i in $(ibdev2netdev |awk '{print $5}')
do
mlnx_qos -i $i --pfc '0,0,0,1,0,0,0,0'
mlnx_qos -i $i --trust dscp
echo 1 > /sys/class/net/$i/ecn/roce_np/enable/3
echo 1 > /sys/class/net/$i/ecn/roce_rp/enable/3
echo 48 > /sys/class/net/$i/ecn/roce_np/cnp_dscp
done
for i in $(ibdev2netdev |awk '{print $1}')
do
cma_roce_mode -d $i -p 1 -m 2
echo 120 > "/sys/class/infiniband/$i/tc/1/traffic_class"
cat "/sys/class/infiniband/$i/tc/1/traffic_class"
cma_roce_tos -d $i -t 120
done
sysctl -w net.ipv4.tcp_ecn=1
root@gpu5:~# bash rdma.shLoading the RDMA Sharp Acceleration Library
root@gpu:~# tar -xpvf nccl-rdma-sharp-plugins.tar.gz
root@gpu:~# cd nccl-rdma-sharp-plugins
root@gpu:~# ./autogen.sh
root@gpu:~# ./configure --libdir=$(pwd)/build --with-cuda=/usr/local/cuda
root@gpu:~# make
root@gpu:~# make install
root@gpu:~# export \
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/root/nccl-rdma-sharp-plugins/build/HPC Scenario

The E2E forwarding performance testing method is similar to the one mentioned above and will not be repeated here.
MPI Benchmark Test Environment Deployment
- The MPI test is divided into point-to-point communication and network communication, covering data sizes from 2 to 8,388,608 bytes.
#HPC infrastructure
[root@Server ~]# cat /etc/hosts
[root@Server ~]# systemctl stop firewalld && systemctl disable firewalld
[root@Server ~]# iptables -F
[root@Server ~]# setenforce 0
[root@Server ~]# ssh-keygen
[root@Server1 ~]# ssh-copy-id -i id_rsa.pub root@192.168.4.145
[root@Server2 ~]# ssh-copy-id -i id_rsa.pub root@192.168.4.144
[root@Server1 ~]# yum -y install rpcbind nfs-utils
[root@Server1 ~]# mkdir -p /data/share/
[root@Server1 ~]# chmod 755 -R /data/share/
[root@Server1 ~]# cat /etc/exports
/data/share/ *(rw,no_root_squash,no_all_squash,sync)
[root@Server1 ~]# systemctl start rpcbind
[root@Server1 ~]# systemctl start nfs
[root@Server2 ~]# yum -y install rpcbind
[root@Server2 ~]# showmount -e Server1
[root@Server2 ~]# mkdir /data/share
[root@Server2 ~]# mount -t nfs Server1:/data/share /data/share
#OSU MPI Benchamarks Tool Installation
[root@Server ~]# yum -y install openmpi3 openmpi3-devel -y
[root@Server ~]# wget \
http://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.6.3.tar.gz
[root@Server ~]# tar zxvf osu-micro-benchmarks-5.6.3.tar.gz
[root@Server ~]# cd osu-micro-benchmarks-5.6.3
[root@Server ~]# ./configure
[root@Server ~]# make -j
[root@Server ~]# make install
[root@Server ~]# mkdir /osu
[root@Server ~]# cp -rf \
/usr/mpi/gcc/openmpi-4.0.3rc4/tests/osu-micro-benchmarks-5.3.2/* /osuHPC Application Deployment
- The test results represent the time taken by both the test device and the control group to complete the same computational task. The final result is the average time taken from three consecutive tests.
To deploy the WRF (Weather Research and Forecasting) simulation, the server must first have the compiler installed and the basic environment variables configured. Next, third-party libraries such as zlib, libpng, mpich, jasper, and netcdf need to be compiled, followed by testing the dependency libraries. Afterward, the WRF application and WPS (WRF Preprocessing System) are installed. Finally, the executable file is generated.
#Run WRF
[root@Server1 em_real]# time /usr/mpi/gcc/openmpi-4.1.5a1/bin/mpirun -np 24 -oversubscribe --allow-run-as-root \
--host 1.1.3.2,1.1.2.2 ./wrf.exeBefore running LAMMPS, GCC, OpenMPI, and FFTW need to be compiled and installed.
#Run LAMMPS
[root@Server1 ~]# cd ~/lammps/lammps-stable_3Mar2020/examples/shear
[root@Server1 ~]# vi in.shear
atom_style atomic
region box block 0 16.0 0 10.0 0 2.828427
create_box 100 box
thermo 25
thermo_modify temp new3d
timestep 0.001
thermo_modify temp new2d
reset_timestep 0
run 340000
[root@Server1 ~]# mpirun --allow-run-as-root -np 4 –oversubscribe \
--host 1.1.3.2,1.1.2.2 lmp_mpi \
< /root/lammps/lammps-3Mar20/examples/shear/in.shearThe control group InfiniBand switch is the Mellanox MSB7800.
Distributed Storage

The FIO tool (Flexible IO Tester) is used to stress-test the distributed storage system. The peak value, calculated from IOPS x IO Size, represents the system’s maximum throughput capacity.
IOPS is measured through random read and random write tests, using different block sizes (4k/8k/1024k).
#Server-side configuration
[root@mstor ~]# cat RDMA.sh
#!/bin/bash
for mlx_dev in $(ibdev2netdev | awk '{print $1}')
do
if_dev=$(ibdev2netdev | grep $mlx_dev | awk '{print $5}')
ifconfig "${if_dev}" mtu 9000.
cma_roce_tos -d "${mlx_dev}" -t 120
mlnx_qos -i "${if_dev}" --trust dscp
mlnx_qos -i "${if_dev}" --pfc 0,0,0,1,0,0,0,0
mlnx_qos -i ${if_dev} --dscp2prio set,30,3
echo 48 >/sys/class/net/${if_dev}/ecn/roce_np/cnp_dscp
echo 1 >/sys/class/net/${if_dev}/ecn/roce_np/enable/3
echo 1 >/sys/class/net/${if_dev}/ecn/roce_rp/enable/3
cma_roce_mode -d ${mlx_dev} -p 1 -m 2
sysctl -w net.ipv4.tcp_ecn=1
echo 120 > /sys/class/infiniband/"${mlx_dev}"/tc/1/traffic_class
done
[root@mstor ~]# ./RDMA.sh#Switch-side configuration
sonic@sonic:~$ sudo config cli-mode cli
sonic@sonic:~$ sudo sonic-cli
sonic# configure terminal
sonic(config)# vlan 100
sonic(config-vlan-100)# interface ethernet 0/0
sonic(config-if-0/0)# switchport access vlan 100
sonic(config-if-0/0)# interface ethernet 0/4
sonic(config-if-0/4)# switchport access vlan 100
sonic(config-if-0/4)# exit
sonic(config)# policy-map pmap1
sonic(config-pmap-pmap1)# queue-scheduler priority queue 6
sonic(config)# interface ethernet 0/0
sonic(config-if-0/1)# service-policy pmap1
sonic(config)# access-list table_1 l3 ingress
sonic(config-l3-acl-table_1)# bind interface ethernet 0/0
sonic(config-l3-acl-table_1)# rule 1 source-ip 10.10.12.18 set-dscp 30 set-tc 3
sonic(config-l3-acl-table_1)# bind interface ethernet 0/4
sonic(config-l3-acl-table_1)# rule 1 source-ip 10.10.12.19 set-dscp 30 set-tc 3About Asterfusion
Asterfusion is a leading innovator in open-network solutions, offering cutting-edge products like 1G-800G SONiC-based open network switches, DPU NICs, and P4-programmable hardware. We provide fully integrated, ready-to-deploy solutions for data centers, enterprises, and cloud providers. With our flexible, decoupled hardware and our self-developed enterprise SONiC distribution, we empower customers to build transparent, easy-to-manage, and cost-efficient networks—designed to thrive in an AI-driven future.



