Table of Contents
What is MTU?
MTU (Maximum Transmission Unit) is the largest packet size that can be transmitted over a network link without fragmentation. It is typically measured in bytes.
For standard Ethernet networks, the default MTU is 1500 bytes (1500B). This value usually refers to the maximum size of the IP packet (IP payload plus IP header) that can be carried in a single Ethernet frame. In some cases, the MTU can also be configured to a value smaller than 1500 bytes.
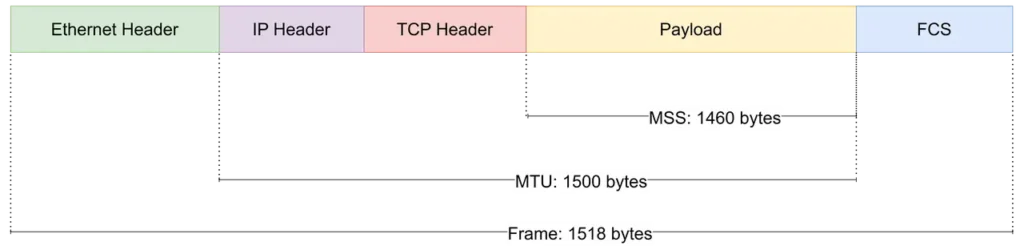
MSS: Maximum Segment Size. MSS refers to the maximum amount of TCP payload that can be carried in a single TCP segment.
When a packet exceeds the MTU of a network link, it cannot be transmitted as a single packet. Depending on the outgoing interface configuration and the packet’s Don’t Fragment (DF) flag, the packet is either fragmented into multiple IP packets or discarded.

Assume Host A needs to send data to Host B.
Host A first constructs the packet. The upper-layer protocol passes the data to the IP layer, which prepares an IP datagram for transmission.
Before sending the packet, the IP layer checks the MTU of the outgoing interface. If the packet size exceeds the interface MTU, the IP layer determines whether fragmentation is allowed. If fragmentation is permitted, the original IP datagram is divided into multiple fragments. Each fragment contains its own IP header. The receiving host reassembles the original packet using the Identification, More Fragments (MF) flag, and Fragment Offset fields in the IP header.
If fragmentation is not allowed, or the packet has the DF flag set, the packet is dropped instead. In most cases, the router returns an ICMP “Fragmentation Needed” message to the sender. If ICMP messages are blocked, Path MTU Discovery (PMTUD) cannot detect the MTU limitation, which may result in a PMTU black hole where packets are silently discarded.
What Happens When Using an MTU of 1500 in an AI Data Center?
Based on the concepts above, let’s look at what happens when the standard 1500-byte MTU is used in an AI data center. Modern AI clusters commonly operate over 400G or 800G links and transfer massive amounts of data during GPU training. If the MTU remains at 1500 bytes, several issues become apparent.
- Packet Rate Increases Dramatically
On 400G and 800G links, a 1500-byte MTU divides the same amount of data into a much larger number of packets. As a result, the NIC, switch ASIC, CPU, and PCIe bus must process significantly more packets per second. This directly increases per-packet processing overhead and reduces overall system efficiency.
- Lower Payload Efficiency
With a 1500-byte MTU, Ethernet, IP, and TCP headers consume a larger percentage of each packet. During AI training workloads such as checkpoint transfers, parameter synchronization, and distributed storage access, the link may appear fully utilized, but a larger portion of the bandwidth is spent carrying protocol headers instead of application data. The effective payload ratio is therefore lower.
- Tunnel Encapsulation Makes MTU Exhaustion More Likely
AI data centers widely deploy overlay technologies such as VXLAN, EVPN, and SRv6. These encapsulation headers consume part of the available MTU, reducing the space left for the original packet. As a result, packets are much more likely to exceed the path MTU, triggering fragmentation or packet drops. Both can significantly disrupt the synchronized communication required by distributed AI training.
- PMTUD Black Holes Make Troubleshooting More Difficult
PMTUD depends on ICMP messages to discover the maximum packet size supported along a path. In real-world networks, ICMP packets are often filtered or misconfigured, causing PMTUD to fail and creating a PMTU black hole.
The symptoms can be confusing. Small packets, such as ICMP ping requests, are transmitted successfully, making the network appear healthy. However, large AI data flows experience timeouts or packet loss because oversized packets are silently dropped. In large-scale AI fabrics, this type of issue can be particularly difficult to identify and troubleshoot.
- Cluster Stability Becomes More Sensitive to MTU Mismatches
Modern AI infrastructures often span multi-tenant environments, Kubernetes clusters, overlay networks, and hybrid cloud deployments. If any component along the forwarding path—including a server, VPC, load balancer, network virtual appliance (NVA), or the underlying fabric—uses a smaller MTU, performance degradation or intermittent connectivity issues become much more likely.
Standard 1500-byte MTU was designed for traditional IP networks carrying web, enterprise, and general TCP traffic. These workloads typically run on lower-bandwidth networks and can tolerate occasional retransmissions caused by packet loss.
AI data centers have very different requirements. Distributed GPU training depends on extremely high throughput, ultra-low latency, and deterministic communication between nodes. Under these conditions, a 1500-byte MTU becomes a performance bottleneck. This is why AI networks commonly adopt Jumbo Frames to reduce packet processing overhead, improve bandwidth efficiency, and deliver more predictable performance.
What is a Jumbo Frame
A Jumbo Frame is an Ethernet frame that exceeds the standard 1518-byte frame size defined by IEEE 802.3. In AI data centers, Jumbo Frames are typically enabled by configuring the MTU (Maximum Transmission Unit) to 9000 bytes or higher.
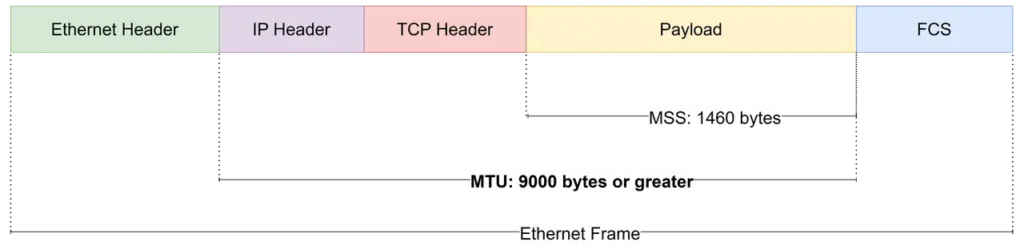
Jumbo Frames are widely used in storage networks, HPC clusters, and AI data centers where large volumes of data are transferred continuously.
Why Do AI Data Centers Need Jumbo Frames?
The reason is straightforward. A larger MTU allows each packet to carry more payload, so the same amount of data can be transmitted using far fewer packets.
A wider data path for large AI workloads: Jumbo Frames effectively increase the network’s “pipe diameter.” Large data transfers, such as AI model weight distribution, distributed parameter synchronization, and checkpoint replication, can traverse the network more efficiently without being slowed by excessive packet processing or frequent fragmentation.
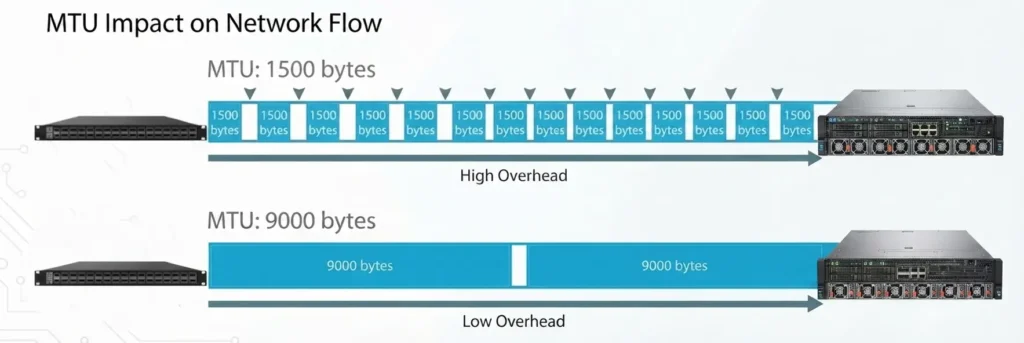
Fewer interrupts and lower CPU overhead: Transferring 10 GB of data requires approximately 7.15 million packets with an MTU of 1500 bytes, but only about 1.2 million packets with a 9000-byte Jumbo Frame. This represents an 83% reduction in packet count. As a result, the CPU handles far fewer interrupts, significantly reducing overall system overhead.
Higher throughput efficiency: Because protocol headers account for a smaller percentage of each packet, a greater portion of the link bandwidth is used for application payload. This improves bandwidth utilization and allows throughput to approach the physical limits of the network.
Although Jumbo Frames provide significant performance benefits, they must be deployed carefully. In AI data centers, the following considerations are especially important.
- End-to-end MTU consistency is critical: Every device along the forwarding path—including NICs, switches, virtualization layers, tunnel endpoints, and destination hosts—must support the same MTU. For example, if both the servers and switches are configured with an MTU of 9000, but an intermediate device such as a firewall or load balancer supports only 1500, large packets will either be fragmented or dropped. Fragmentation increases CPU utilization and packet reassembly overhead, while packet drops can lead to communication failures.
- Packet loss becomes more expensive: A Jumbo Frame carries significantly more data than a standard Ethernet frame. If a single large frame is lost, more data must be retransmitted, increasing the recovery cost. On links with frequent packet loss or unstable network conditions, this can amplify performance degradation instead of improving it.
- Latency-sensitive traffic may be affected: Larger frames occupy the physical link for a longer transmission time because Ethernet sends data serially, bit by bit. As a result, small latency-sensitive packets, such as control messages, heartbeat packets, RPC requests, or voice traffic, may spend more time waiting in the transmission queue, introducing additional queuing latency.
- Compatibility and operations become more complex: Many network issues are caused by MTU-related configuration problems rather than insufficient bandwidth. Common examples include MTU mismatches, PMTUD black holes, packets exceeding the MTU after tunnel encapsulation, and intermediate devices that do not support Jumbo Frames. These issues can be difficult to diagnose in large-scale AI data center networks.
Setting the Proper MTU in an AI Data Center Network
In a Rail-Optimized GPU Fabric built with the Asterfusion CX864E-N, the MTU directly affects the efficiency and stability of large-scale GPU communication. For a 400G RoCEv2 network, follow these engineering practices when configuring the MTU.
1. Maintain End-to-End MTU Consistency
In a GPU fabric, every device along the data path—including GPU NICs and switch ports—must use the same MTU value.
- Supported range: 1312 to 9216 bytes in AI ethernet switches.
- Recommended setting: For 400G RoCEv2 networks, use the default 9216-byte MTU to maximize throughput and minimize protocol overhead.
2. Validate the Entire Forwarding Path
Configuring only the GPU servers and the first-hop switch is not sufficient. Before deploying the network, verify that the entire forwarding path supports the target MTU.
- Check every device: Ensure that all switches, gateways, firewalls, load balancers, and other intermediate devices support Jumbo Frames.
- Verify hardware limits: Confirm that every device on the path can forward 9216-byte frames. A single device with a lower MTU can introduce fragmentation or packet drops, affecting the entire GPU fabric.
3. Configure the MTU
For the detailed configuration procedure, refer to Interface Base Configuration.
Conclusion
As AI models continue to grow in size, network efficiency becomes increasingly important. A high-performance AI data center requires a network that delivers predictable performance with minimal overhead. Understanding MTU behavior and deploying Jumbo Frames with consistent end-to-end configuration helps eliminate unnecessary fragmentation, reduce packet processing overhead, and fully utilize GPU cluster performance.
When deploying an AI cluster, ensure that your network switches can process Jumbo Frames at line rate. If you are planning a large-scale GPU deployment, contact our networking experts to discuss your requirements and receive guidance on optimizing your AI network architecture.



