Table of Contents
Introduction
When buying a switch, you might not pay attention to which chip it uses, but you will definitely care about its performance—such as the size of the routing table, the level of throughput, and the degree of latency. In fact, all these key capabilities depend on the chip.

Ⅰ. Marvell Falcon 2.0T Chip : Leaf Layer Routing Expert
Currently, Asterfusion’s data center products mainly adopt two types of core chips: Marvell Teralynx and Falcon. Let’s start with Falcon—what makes its positioning and performance stand out?

1. Product Positioning
The Marvell Falcon series of chips is different from those traditional Ethernet chips that only pursue “high – speed forwarding” and high – port density. It pays more attention to the integrity and scalability of routing functions. In large – scale data centers, it can bear massive routing tables and neighbor tables, ensuring that each data packet can reach its destination smoothly.
For example, if you operate a public cloud or a large – scale private cloud platform, tenant isolation, frequent virtual machine migrations, and complex BGP routing strategies will put a lot of pressure on the switch control plane. Relying solely on traditional Ethernet chips, it is very easy to encounter problems such as insufficient routing tables or slow updates. Falcon is designed to solve such problems – not only does it have a large routing table capacity, but it also optimizes the processing of routing protocols at the hardware level, so it can remain stable and flexible in complex environments.
2. Chip Performance
The Falcon 2.0T chip delivers outstanding performance with the following key highlights:

First, it offers high-performance forwarding capabilities. It supports large-scale L2/L3 forwarding and routing table processing, while easily meeting the demands of VXLAN/VRF multi-tenant isolation. Even in complex encapsulation scenarios such as VXLAN-GPE and Geneve, it enables high-speed hardware-level forwarding.
Second, the chip features multi-rate FlexLink technology, allowing ports on the same chip to operate at different rates without requiring uniform configuration. This offers greater flexibility across diverse service scenarios.
Additionally, the Falcon 2.0T provides high port density and powerful throughput. It supports 48 or more high-density ports with a total bandwidth of 2 Tbps and a forwarding capacity of up to 2.8 Bpps. It excels in handling east-west traffic at the ToR aggregation layer, all while maintaining efficient power consumption.
In terms of control plane and virtualization, the chip supports large-scale VRF/VXLAN isolation and is compatible with protocols including BGP, OSPF, and IS-IS, enabling rapid routing convergence and neighbor information synchronization. Even during frequent virtual machine or container migrations, service continuity is ensured.
Notably, the Marvell Falcon 2.0T/3.2T/4T/6.4T family supports both one-step and two-step Precision Time Protocol (PTP) according to the IEEE 1588v1/v2 standard. This enables high-accuracy clock synchronization, which is essential for data center time-sensitive applications such as financial trading and time-based SDN updates.
For detailed specifications, please refer to Falcon 2.0T (Prestera 98CX85xx)
Ⅱ. Marvell Teralynx Chip: Spine Layer Performance Core
Next, let’s take a look at the Teralynx chip.

1. Product Positioning
The Marvell Teralynx series is designed for the spine layer and large-scale aggregation layer of data centers. It emphasizes extreme throughput, ultra-low latency, and high-capacity routing tables, enabling stable aggregation of east-west traffic from hundreds of leaf switches.
For example, in public cloud or extremely large private cloud environments, numerous leaf/ToR switches forward aggregated traffic to the spine layer, where traffic bursts and east-west transmissions occur frequently. If the spine-layer chip relies solely on basic forwarding capabilities without optimized throughput and low-latency processing, it can easily suffer from queue congestion or accumulated latency. Equipped with a large-scale high-speed forwarding architecture and a scalable buffer design, Teralynx efficiently and reliably handles the demanding traffic aggregation requirements of spine-layer networks.
2. Chip Performance
The Teralynx series demonstrates outstanding capabilities in the following key areas:
First, it delivers exceptional throughput and ultra-low latency. Even under high port density, the chip achieves total throughput of several terabits per second (Tbps) while maintaining minimal latency. This ensures stable and reliable performance in spine-layer aggregation for massive east-west traffic and multi‑tenant virtualized networks.
Furthermore, Teralynx supports high-density port configurations and multi-rate interfaces. It offers between 64 and 128 ports with speeds ranging from 10G to 400G per port, providing deployment flexibility across diverse scenarios.
In terms of control plane and routing scalability, Teralynx accommodates large-scale L2/L3 and VXLAN table sizes, supports mainstream routing protocols, and delivers rapid convergence.
For virtualization and encapsulation, the chip incorporates a programmable header processing engine capable of natively handling advanced encapsulation protocols such as VXLAN-GPE, Geneve, and NSH. This enables efficient processing in complex multi-tenant cloud environments.
Finally, Teralynx offers excellent scalability and large-scale deployment capabilities. Its high-performance buffer architecture and multi-stage pipeline ensure low latency and high reliability even when aggregating traffic from hundreds of leaf switches.
For detailed specifications, please refer to Teralynx 7 and Teralynx 10.
Note: One important distinction is that PTP is not supported by Teralynx 7, whereas Falcon impressively supports this feature. This enables switches based on Falcon 2.0T to be deployed in time-sensitive scenarios at the leaf layer, such as financial trading.
Ⅲ. Marvell Teralynx and Falcon Comparison with Asterfusion Switches
To help you understand the application scenarios of different chips in data centers, we have compiled a comparison of the core functions and performance of three mainstream Marvell chip models.
| Comparison Item | Marvell Falcon 2.0T (98CX8514) | Teralynx 7 (IVM77500 / IVM77700) | Marvell Teralynx 10 |
| Core Positioning | Routing Expert | Balanced Performance Core | Performance Pinnacle in the AI Era |
| Typical Scenarios | ToR/Leaf Aggregation, Targeting Standalone Servers or Rack Servers | Spine/Large-Scale Aggregation Layer, Targeting Aggregation of Hundreds of Leaf Switches | Ultra-Large-Scale AI Clusters, Cloud Core, Next-Generation 800G Data Center Backbone |
| Key Focus | Routing Function Integrity and Scalability | Extreme Throughput, Low Latency, High-Density Aggregation | Ultimate Performance, Advanced AI Network Features |
| Switching Capacity | 2.0 Tbps | 3.2T / 6.4T / 12.8 Tbps | 51.2 Tbps |
| Latency | ~1,400 ns | ~500 ns | ~560 ns (Cut-Through) |
| PTP | Supported | Not Supported | Supported |
| Asterfusion Product | CX308P-48Y-N-V2 | CX532P-N, CX564P-N, CX664D-N, CX732Q-N | CX864E-N |
In summary, the Falcon 2.0T is better suited for the ToR/Leaf Layer—notably, it supports PTP for time-sensitive applications—while the Teralynx 7 targets the Spine Aggregation Layer, and the Teralynx 10 is designed for ultra-large-scale AI and cloud core networks.
Leveraging these chips, Asterfusion provides the CX-N Series switches, which are tailored to various application scenarios and capable of meeting diverse requirements—from small data centers to large-scale cloud environments.
Ⅳ. Role of Marvell Teralynx and Falcon in Spine-Leaf Architecture
In a typical spine-leaf architecture, Falcon and Teralynx chips work together to deliver comprehensive coverage across all data center network scenarios. This combination enables both the server access layer and the core aggregation layer to achieve high-speed, stable, and scalable traffic processing.
The following diagram illustrates a schematic of the Spine-Leaf architecture:
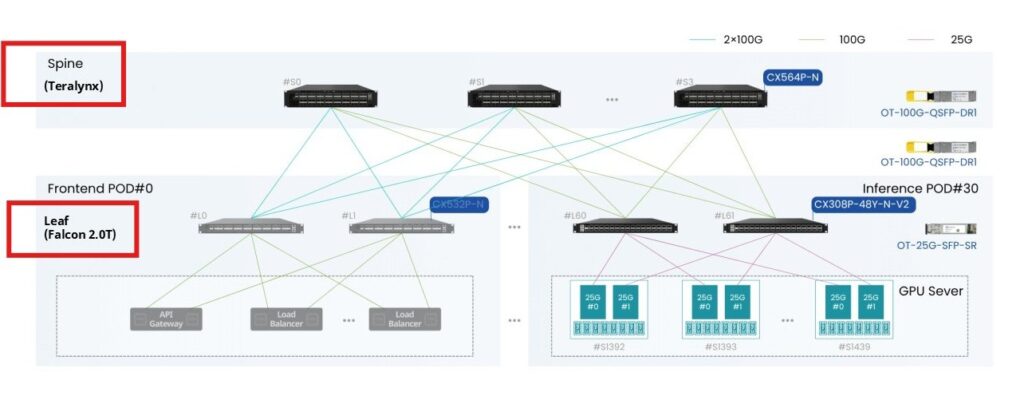
Spine Layer (Teralynx Chips): In charge of high-speed forwarding and functioning as the core backbone of the network.
Leaf Layer (Falcon Chips): Directly connects to servers, and undertakes the tasks of managing large routing tables and supporting Layer 3 functions.
Server Layer: Gains access to the data center network through connection to the Leaf layer.
The diagram above clearly illustrates the collaboration mechanism between these layers. This architecture not only improves network efficiency but also provides a scalable foundation for future data center expansion and diverse application deployment.
Ⅴ. AsterNOS Software: Unlocking Marvell Chip Potential
We emphasize software alongside chips because while Marvell Teralynx and Falcon chips provide fundamental “hard capabilities”—such as compute power and table entries—the flexible performance required in complex data center environments depends heavily on software-based scheduling and coordination. Without software, hardware remains a set of isolated components, incapable of dynamic optimization in response to changing business demands.
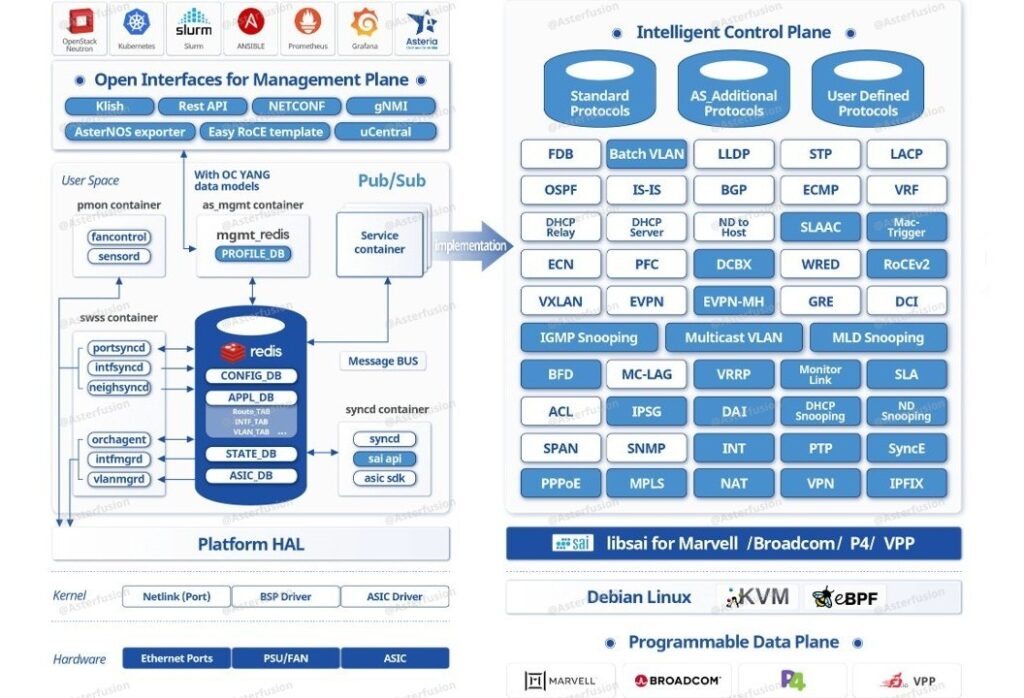
AsterNOS, developed based on open-source SONiC, acts as this essential coordinator: it integrates capabilities including L2/L3 protocols, VXLAN, VRF, and multi-tenant isolation. By leveraging tools such as ZTP, Ansible, Prometheus, and Grafana, it streamlines deployment and management while enabling real-time network visibility. Furthermore, it enhances performance in demanding scenarios such as QoS and RoCE.
In summary, Marvell Teralynx and Falcon chips define the fundamental capabilities—what can be done—while AsterNOS controls the implementation and performance—how it is done and how well. Together, they integrate discrete hardware resources into a cohesive system, enabling Asterfusion switches to deliver optimal value in real-world business applications.
Ⅵ. Conclusion
In a Spine-Leaf architecture, Marvell Falcon 2.0T chips are optimized for the Leaf/ToR layer, delivering advanced routing capabilities, multi-tenant support and PTP for time-sensitive scenarios, while Marvell Teralynx chips excel in the Spine layer, providing extreme throughput and ultra-low latency. Together, they form a high-performance backbone that meets the stringent performance, scalability, and stability requirements of modern data centers.
Leveraging these two chip series, Asterfusion has introduced the CX-N series switches. Integrated with the self-developed AsterNOS operating system, these switches enable deep hardware-software coordination, unlocking full Marvell Teralynx and Falcon chips potential and offering enterprises and cloud data centers a comprehensive, high-efficiency solution.
For another perspective on Marvell Teralynx and Falcon, please click here.
Related Products:










