Table of Contents
According to a new report from The Information, Microsoft and OpenAI are building a massive data center called “Stargate” for an AI supercomputer. The project could cost more than $100 billion. Microsoft is using InfiniBand cables in its current project, while OpenAI favors the Ethernet over IB for its network infrastructure.


Self-developed White Box Switch or IB switches?
Today, it seems easier than ever to self-develop high-end Ethernet switches as IB alternatives.
Instead of a few communication manufacturers relying on large chassis and backplanes, now we can use CLOS architecture to remove the performance limitations of switch backplanes and use common hardware design for high-performance networking. In addition, in the era of “software-defined everything”, the standard SAI and open source SONiC provide more flexible, customizable and high-performance network solution options. Maybe that’s why we’ve seen a number of large enterprises such as Byte-dance, Alibaba, begin to develop their own switches based on whiteboxes.
Nonetheless, for the absolute majority of organizations or enterprises interested in building their own AI or HPC clusters, the time cost of developing their own switches is much higher than purchasing switch products. Obviously self-developed white box switch not a reasonable option.
Whitebox Switch Vendors or Solution Provider for AI, HPC and Cloud?
Not only are companies like OpenAI and Microsoft considering Ethernet infrastructure, but because of the problems associated with the high concentration of vendors supplying InfiniBand switches ( the long lead times, high prices, etc.), many Tier 2 to 3 CSPs and some AI-related companies have been considering RoCE (RDMA over Converged Ethernet) as an alternative to InfiniBand for a long time.
Today’s white box switch vendors include Pica8, IP Infusion, Agema Systems, Foxconn Technology, Edgecore Networks, Celestica, Asterfusion Data Technologies and others.
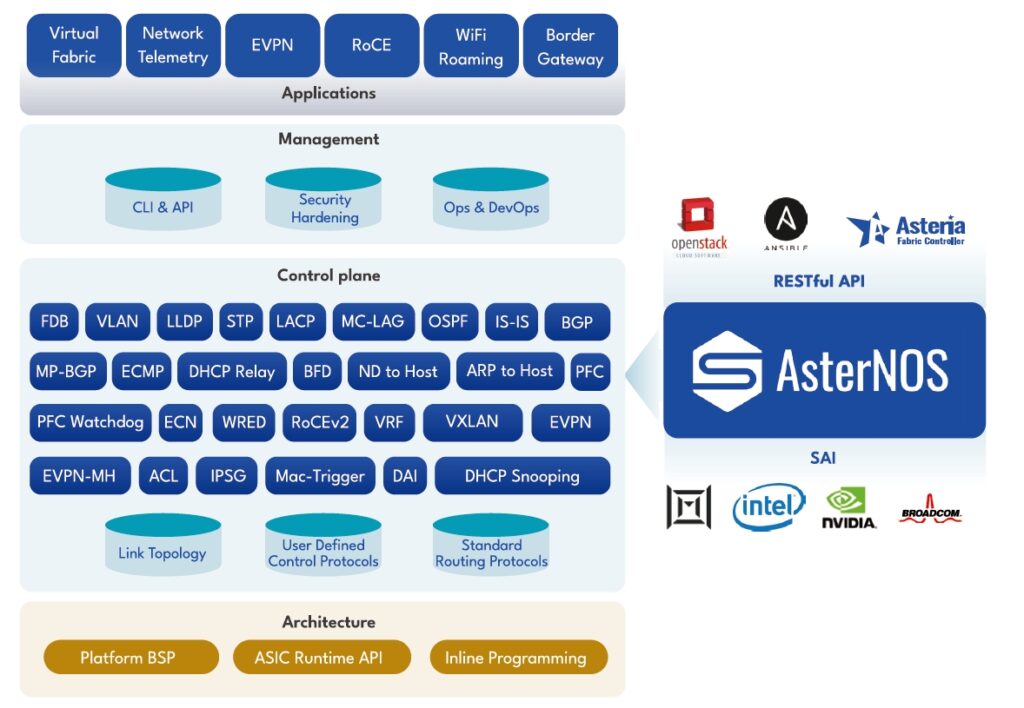
Among this, Asterfusion has been crafting their enterprise SONiC operating system (AsterNOS) since 2017 to provide a turnkey open network solution, which is one of the few vendors to offer both enterprise-ready SONiC distribution and whitebox switch hardware (according to a recent Gartner report ).
Asterfusion AI Network Solution with NVIDIA DGX SuperPOD
Your AI/ML computing cluster, hungering for speed and reliability, fueled by the power of 800G/400G/200G Ethernet, RoCEv2 technology, and intelligent load balancing. This isn’t just any connection – it’s a high-performance, low-TCO network powerhouse, courtesy of Asterfusion. No matter the size of your cluster, we’ve got you covered with our one-stop solution.
For more about Asterfusion AI network solution :https://cloudswit.ch/solution/rocev2-ai-solution-with-dgx-superpod/
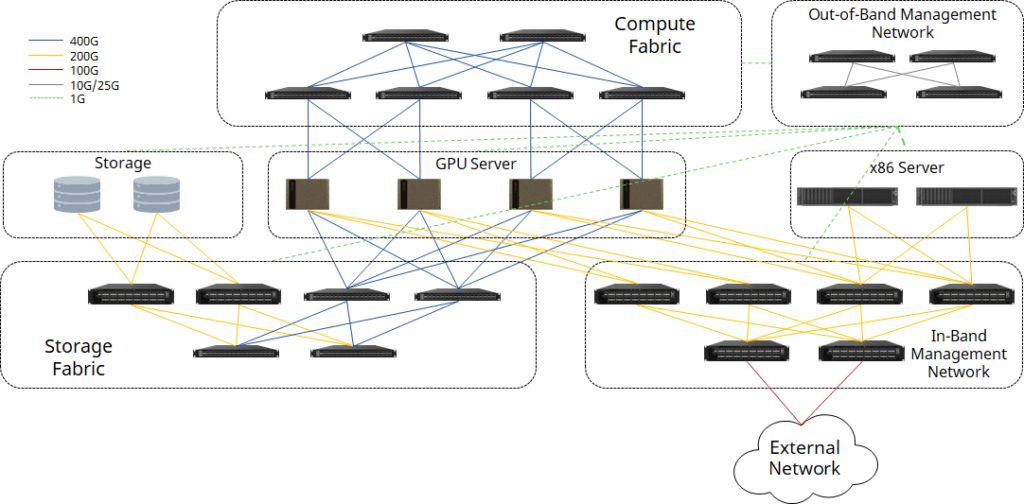
Compute Fabric
For a research project or PoC, starting with a small-scale cluster is a good choice. Less than 4 nodes DGX H100 can be connected with one single 32x400G switch, using QSFP-DD transceivers on switch ports and OSFP transceivers on ConnectX-7 NIC of each GPU server, connecting by MPO-APC cables.

When the number of GPU servers increases to 8, a 2+4 CLOS fabric can be applied. Each leaf switch connects 2 of 8 ports of each GPU server, to archieve a rail-optimized connectivity to increase the efficiency of GPU resources. Spine and leaf switches can be connected through QSFP-DD transceivers with fiber, or QSFP-DD AOC/DAC/AEC cables.

Single CX864E-N (51.2Tbps Marvell Teralynx 10 based 64x800G switch, coming in 2024Q3) can hold even up to 16 GPU servers:

A scalable compute fabric is built upon modular blocks, which provides a rapid deployment of multiple scales. Each block contains a group of GPU servers and 400G switches (16 x DGX H100 systems with 8 x CX732Q-N in this example). The block is designed as rail-aligned and non-oversubscribed, to ensure the performance of the compute fabric.

A typical 64-node compute fabric design is to use Leaf-Spine architecture to hold 4 blocks:

To scale the compute fabric, higher throughput switches can be used to replace the Spine. CX864E-N can be placed here to expand the network to maximum 16 blocks of 256 nodes:

Table 1 shows the number of switches and cables required for the compute fabric of different scales.

In-Band Management Network
The in-band network connects all the compute nodes and management nodes (general-purposed x86 servers), and provides connectivity for the in-cluster services and services outside of the cluster.

Out-of-Band Management Network
Asterfusion also offers 1G/10G/25G enterprise switches for OOB, which also support Leaf-Spine architecture to achieve management of all the components inside the superPOD.

100G-800G Whitebox Switches and Turnkey SONiC Solution by Asterfusion
Asterfusion provides network switches ranging from 100G to 800G port capacities for Cloud and AI.
Whether tested in AIGC networks, HPC or distributed storage networks, Asterfusion’s RoCEv2 Ethernet switches meet or exceed the performance of infiniband switches, but are half the price of infiniband switches.




For the AI computing clusters required for LLM-training, cutting unnecessary cross-GPU server links without sacrificing performance will greatly reduce user network construction costs. With only one layer of rail switches and ultra low packet forwarding latency(~400ns), we can minimized the AIGC/ML communication overhead. If you are interested in a detailed solution and would like to receive on-site test results, please feel free to contact us by e-mail (bd@cloudswit.ch).



