Table of Contents
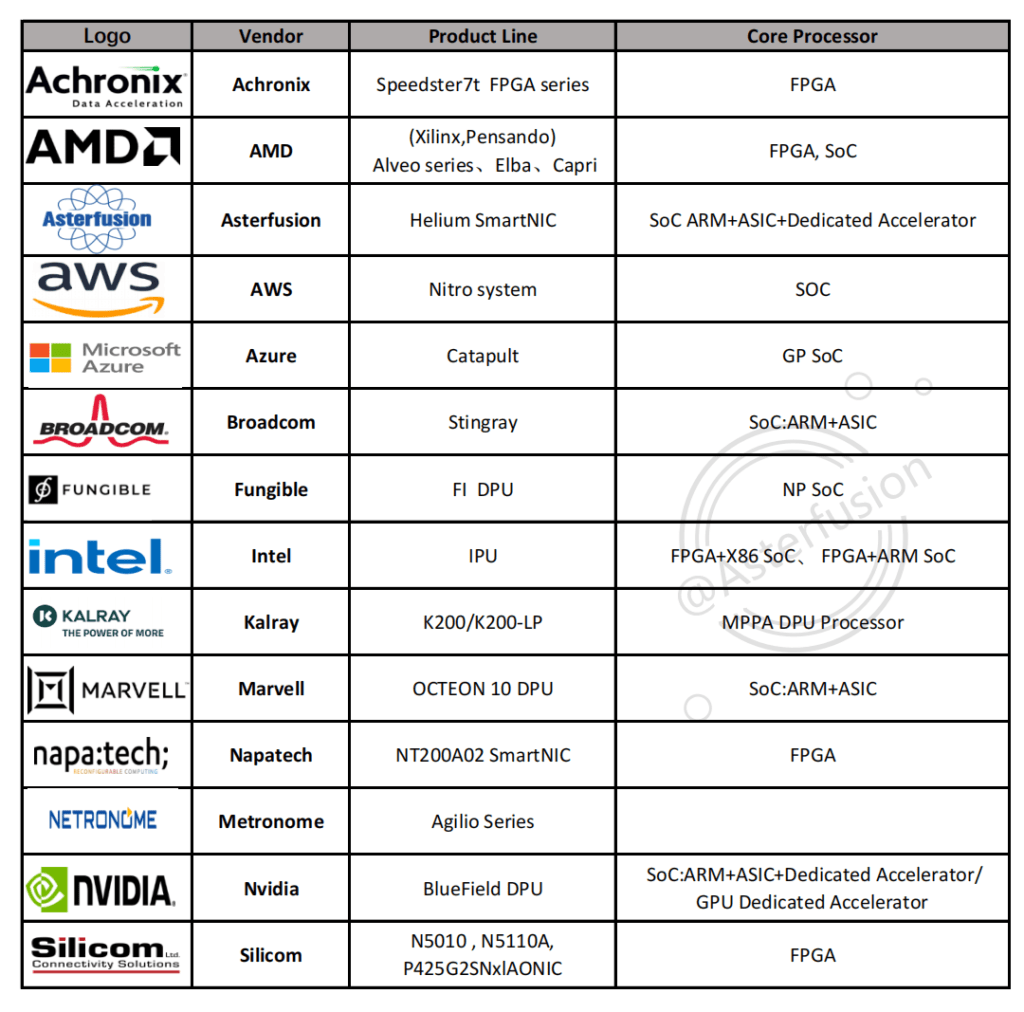
DPU/SmartNIC vendors & product lines include:
- Achronix : Speedster7t FPGA series- FPGA
- AMD(Xilinx;Pensando) Alveo series、Elba、Capri – FPGA, SoC
- Asterfusion: Helium SmartNIC– SoC ARM+ASIC+ Dedicated Accelerator
- AWS:Nitro system – SOC
- Azure : Catapult – GP SoC
- Broadcom: Stingray – SoC:ARM+ASIC
- Intel :IPU- FPGA+X86 SoC、 FPGA+ARM SoC
- Fungible :Fl DPU – NP SoC
- Kalray :K200/K200-LP – MPPA DPU Processor
- Marvell : OCTEON 10 DPU – SoC:ARM+ASIC
- Napatech : NT200A02 SmartNIC – FPGA
- Netronome : Agilio Series
- Nvidia: BlueField DPU – SoC:ARM+ASIC+Dedicated Accelerator/GPU Dedicated Accelerator
- Silicom :N5010 , N5110A, P425G2SNxlAONIC – FPGA
As a new “hotshot” in data centers,DPU is bound to be fierce battleground for various giants and companies; self-research, mergers and acquisitions, FPGA-based DPU (SmartNIC) ;ASIC (Application-specific integrated circuits) based DPU (SmartNIC); SoC(system-on-chip) based SmartNIC (DPU); various companies use their unique skills to seize this market opportunities.
In this article , we will systematically summarize main DPU vendors & its product lines on the market.
Before starting the text, let’s understand the following concepts:
What is DPU?
- Click for to learn about What is DPU ?
What is SmartNiC
- Click for to learn about What is Smartnic ?

Achronix : Speedster7t FPGA series- FPGA
Achronix Semiconductor is an American fabless semiconductor company ,which provides high-end FPGA-based data acceleration solutions designed to meet the needs of high-performance, compute-intensive, and real-time processing applications. Achronix offers Speedster7t FPGA family and Speedcore eFPGA IP. Users can deploy the technology as a standalone product, ASIC or SoC design. Achronix also offers VectorPath accelerator cards.

Achronix Speedster7t FPGA series optimized for high bandwidth workloads, eliminating performance bottlenecks associated with traditional FPGAs. Speedster7t FPGA is built on TSMC’s 7nm FinFET technology, with new 2D Network on Chip (2D NoC) 、a series of machine learning processor (MLP) workloads optimized for high bandwidth and artificial intelligence/machine learning (AI/ML)、High-bandwidth GDDR6 interface, 400G Ethernet and PCI Express Gen5 ports. It provides ASIC-level performance while retaining the full programmability of an FPGA.
Website:https://www.achronix.com/

AMD(Xilinx;Pensando) Alveo series、Elba、Capri – FPGA, SoC
Founded in 1969,Advanced Micro Devices, Inc. (AMD) is an American multinational semiconductor company,specializing in the design and manufacture of various CPUs, GPUs and other microprocessors for the computer, telecommunications and consumer electronics industries . AMD completes its acquisition of Xilinx in February 2022,the deal, valued at nearly $50 billion, brings AMD Xilinx’s FPGA programmable logic modules and related DSP engines, AI accelerators, memory controllers and other key technologies ,supplemented technical reserves for AMD.
The DPU/SmartNIC provided by Xi linx is the Alveo series, which is based on FPGA. It is capable of accelerating computationally intensive applications, including machine learning inference, data analysis, video transcoding, etc,.


The Alveo series performs 90 times more than the CPU, and can be reprogrammed according to the user’s specific requirements. Since algorithms evolve faster than chip design cycles, programmable hardware that can adapt to changing algorithms is required. Xilinx Alveo SN1000 is the industry’s first SmartNIC to provide software-defined hardware acceleration for offloading all functions in a single platform, which can offload CPU-intensive tasks to optimize network performance, and its architecture can accelerate a variety of custom offloads at wire speed. The SN1000 SmartNIC is based on the Xilinx 16nm UltraScale+™ architecture, powered by a low-latency Xilinx XCU26 FPGA and a 16-core Arm® processor.
In May 2022, AMD announced its acquisition of Pensando Systems in a deal valued at approximately $1.9 billion.
Pensando’s distributed services platform that will expand AMD’s data center portfolio with high-performance data processing units (DPUs) and software stacks.
These products are deployed at scale across cloud and enterprise clients such as Goldman Sachs, IBM Cloud, Microsoft Azure and Oracle Cloud. Pensando’s Elba SoC is a DPU focused on intelligent network switches, and the last Capri DPU was used in the Aruba CX 10000.
Website:https://www.amd.com/en
Asterfusion: Helium SmartNIC– SoC ARM+ASIC+ Dedicated Accelerator
Founded in 2017, Asterfusion Data Technologies delivers a fully open and highly disaggregated network from 1G-400G bare metal switches with SONiC-based commercial operating systems for next-generation data centers, campuses, and service providers. Its cloud network switches, white box hardware, DPU appliance, SmartNiC, and NPB devices are widely used by operators, the Internet, public/private cloud, and other industries.

Helium SmartNIC is self-develop by Asterfusion, equipped with Marvell Octeon CN96XX chip which has 2 models, one provides PCIe x16 Gen4.0 lane 4*25G interface and the other provides 2*100G interface, which is based on a high-performance SoC chip (24-core ARM integrated with multiple hardware-acceleration co-processors). which enables customers to build high-performance intelligent programmable networks while preserving valuable computing resources in servers and reducing the total CAPEX of cloud data centers.

Asterfusion Helium SmartNIC comes with a basic network operating system, FusionNOS- Framework. Network developers can use FusionNOS-Framework as the foundation to develop their own upper-layer applications, thus accelerating application porting & development.
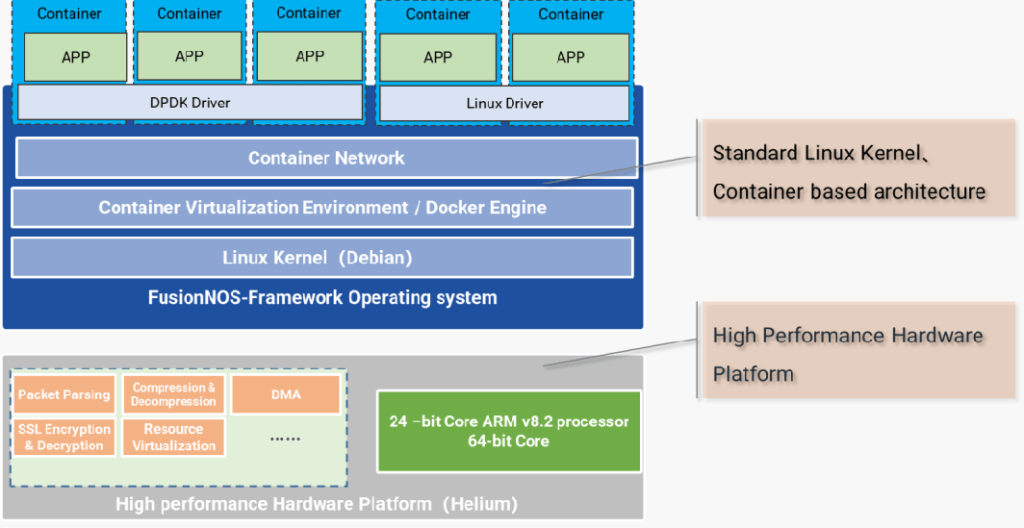
Software Development on Asterfusion SmartNIC
- Through a very simple compilation process various x86-based DPDK applications and generic Linux drivers can be easily ported to Asterfusion Helium SmartNIC.
- DPDK, VPP, SPDK and Ubuntu Support
Asterfusion SmartNIC has various usage, ranging from network acceleration, storage acceleration to security acceleration. Networking functions; Such as VTEP, OVS offload, TCP offload, GRE/GTP tunnel encapsulation and decapsulation, reliable UDP,etc. Security functions: Such as IPSec, SSL, XDP/eBPF, vFW/vLB/vNAT, DPI, and DDoS defense,etc. Storage functions:Such as NVMe-oF (TCP) and data compression/decompression,etc.

AWS: Nitro system – SOC
Tracing the source of DPU, there are two cloud computing giants that realize large-scale commercial DPU architecture: Amazon AWS and Alibaba Cloud. The Amazon Nitro system has been in R&D since 2013 and was officially released in 2017 to maximize performance and security.
The AWS Nitro product family is designed to offload all data center overhead (provides remote resources, encryption and decryption, fault tracing, and security policy services for VMS )from the CPU to the Nitro accelerator card, which will release 30% of the computing power originally used to pay “Tax” for upper-layer applications.
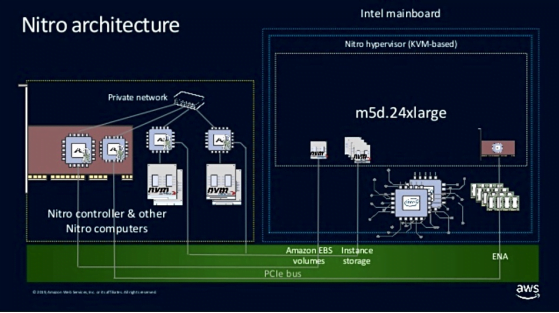
The Nitro system consists of three parts:
- Nitro cards in the form of PCIe cards include Virtual Private Cloud (VPC) cards that support network functions. The Elastic Block Store (EBS) and Instance Storage cards and the Nitro Controller cards support the system control function.
- The Nitro security chip, which provides Hardware Root of Trust, prevents software running on general-purpose servers from modifying non-volatile storage, such as virtual machine UEFI programs.
- Nitro Hypervisor running on general-purpose servers, which is a lightweight hypervisor based on kvm, mainly provides CPU and memory management, and does not provide device simulation (because all devices are added to the virtual machine through transparent transmission) .
Website:https://aws.amazon.com

Azure: Catapult – GP SoC
Azure’s Project Catapult launched its first pilot deployment of FPGA-enabled servers in a data center in 2013, the project shows a significant improvement in latency, running a decision tree algorithm 40 times faster than using the CPU alone while reducing the number of servers.
Azure deployed Catapult v1 in its WCS cloud storage in 2012, later Catapult v2 has been deployed on all newly purchased servers within Bing and Azure. By 2015, Microsoft had massively deployed FPGA into its Azure public cloud, and within a year, its AccelNet initiative introduced FPGA-based SmartNIC as the default hardware for implementing virtual networking capabilities in Azure, And FPGAs are deployed in more than 1 million hosts. In 2017, Azure deployed Catapult v3 to accelerate deep neural networks and increase network speeds in Bing to 50 Gb/sec.
Website:https://azure.microsoft.com/

Broadcom: Stingray – SoC:ARM+ASIC
Broadcom’s Stingray combines a powerful network controllers, high-performance ARM cpus, PCI Express 3.0, performance accelerators, and DDR4 RAM to offload computation-intensive applications from the CPU of host servers.
Stingray provides high packet rates and low latency. Broadcom is based on the logic of NetXtreme E series controllers,designed the NetXtreme-S BCM58800 chip at the core of Stingray,then placed 8 Arm v8 A72 cores clocked at 3 GHz in the cluster configuration.Additionally, the Stingray can be configured with 16 GB of DDR4 memory.

Broadcom also employs TruFlow technology, a configurable flow accelerator for offloading common network flow processes into hardware. From published information, TruFlow can offload tasks such as Open vSwitch (OvS) on hardware. The company also claims that TruFlow implements many classic SDN concepts in hardware, such as classification, matching, and operation. Therefore, Stingray is equipped with two programmable components, TruFlow and a cluster of four 3 GHz dual-core Arm v8 A72 complexes.
Website: https://www.broadcom.com/

Intel :IPU- FPGA+X86 SoC、 FPGA+ARM SoC

Mount Evans is Intel’s first ASIC IPU, developed in partnership with Google Cloud, targeting high-end and hyperscale data center servers. Oak Springs Canyon is Intel’s second-generation FPGA-based IPU platform built with Intel Xeon-D and Agilex FPGAs.
One of the keys to Intel IPU technology is a fast programmable packet processing engine.Whether it’s FPGA or ASIC-based products, customers can program them with P4 and support processes such as finding, revising, encrypting, and compressing.
At the “Intel Vision 2022” conference, Intel announced its latest IPU roadmap, showing the overall plan for IPUs from 2022 to 2026. Intel will continue ASIC + FPGA IPU design, its IPU roadmap is as follows:
- 2022: 200 Gbps IPU launched, code name is Mount Evans and Oak Springs Canyon.
- 2023/2024: Launch of 400 Gbps IPU, codename is Mount Morgan and Hot Springs Canyon.
- 2025/2026 : Launch of 800 Gbps IPU.
In addition, Intel also introduced the IPU’s open source development kit, IPDK, which can be used to write applications for x86 chips and Arm chips such as Marvell Octeon. The toolkit includes functional blocks for customizing and defining workloads, including offloading package processing.
Website:https://www.intel.com/

Fungible: Fl DPU – NP SoC
In 2019, Fungible defined DPU as a new type of data processing unit. Fungible’s F1 DPU is the industry’s first 800Gbps DPU and its flagship product.
Architecturally, the F1 DPU integrates a large number of multi-core processors, all 52 cores are the latest generation MIPS64 R6 kernel, which not only supports hardware virtualization but also separates it into independent control units. F1 DPU adopts a dual emission pipeline design, equipped with 64KB L1 I-cache and 80KB L1 D-cache, and the L1 cache supports data transmission between ccache, the total on-chip L2 cache reaches 32MB.In terms of memory, in addition to integrating 8GB of HBM, the F1 DPU also supports dual-channel DDR4 memory up to 512GB per channel.
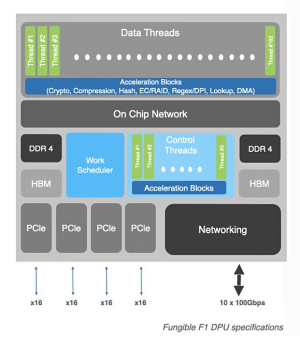
Utilizing a unique combination of hardware and software design, the F1 DPU provides maximum functional flexibility without compromising data center computing energy efficiency. This enables F1 DPUs can use in high performance density and low latency environments such as storage (NVMe/TCP storage offload), security, AI/ML (GPU decoupling) and data analytics servers (OLAP, OLTP big data analytics engine). Taking storage as an example, in a storage system that does not require x86 CPU and AFA, F1 DPU can achieve 15M IOPS performance, and the bandwidth limitation here is entirely from the bandwidth limitation of PCIe itself.
Website:https://www.fungible.com/

Kalray: K200/K200-LP – MPPA DPU Processor
Kalray is a fabless semiconductor company. Founded in 2008 as a spin-off of CEA French lab.
Kalray 3rd Generation MPPA® DPU Processor called Coolidge, which can manage multiple workloads in parallel for smarter, more efficient, and power-efficient data-intensive applications. Leveraging Kalray’s patented MPPA® (Massively Parallel Processor Array) architecture, Coolidge is a scalable 80-core processor designed for intelligent data processing. It provides a unique alternative to GPU, ASIC or FPGA, which brings unique value to multiple applications from data centers to edge and embedded systems.

Based on its MPPA® processors, Kalray’s has developed a series of data-centric accelerator cards, the K200/K200-LP, that provide high performance and a high degree of programmability, which can be used as:
- Accelerator cards, on pure accelerator cards (via PCIe) or inline accelerator cards (via Ethernet), offload the host CPU to dedicated data-intensive applications.
- A stand-alone solution that replaces host processors in some use cases, such as the K200-LP developed for service providers to build their next-generation storage devices.
Website:https://www.kalrayinc.com/

Marvell: OCTEON 10 DPU – SoC: ARM+ASIC
Marvell Technology, Inc. Founded in 1995, is an American company, headquartered in Santa Clara, California, which develops and produces semiconductors and related technology.
Marvell’s OCTEON and ARMADA devices are designed for wireless infrastructure and networking equipment, including switches, routers, security gateways, firewalls, network monitoring, and SmartNICs, And support a comprehensive and unified SDK and open source API for a wide range of network, security and computing applications.
Marvell OCTEON 10 DPU family is optimized for hyperscale cloud workloads, 5G wireless transport, 5G RAN Intelligent Controller (RIC) and edge inference, carrier and enterprise data center applications. It adopts TSMC’s 5nm process technology and ARM’s Neoverse N2 CPU core, plus an array of many functional building blocks of the first-generation OCTEON TX2. It also includes advanced IP and capabilities such as an integrated machine learning inference engine, inline encryption processor, and vector packet processor, all of which can be run in a virtualized manner. As an important complement to the DPU, Marvell is also introducing an in-house machine learning (ML) engine for OCTEON 10.
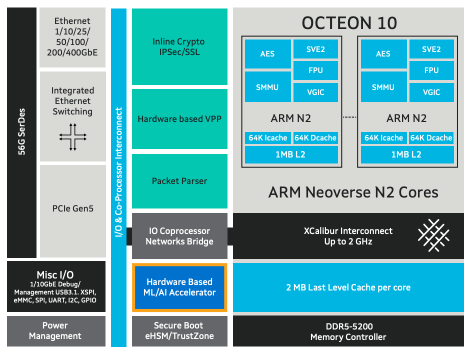
- The industry’s first 5nm DPU with Arm Neoverse N2 core, delivering 3x higher computing performance and 50% lower power consumption than previous generations of OCTEON.
- Innovative hardware accelerators for inline ML/AI provide a 100x performance boost over software-based inference.
- VPP-based hardware accelerators increase packet processing speed by more than 5 times.
- Integrated 1 Terabit switch, true inline encryption, and highly programmable packet processing
- Datapath support over 400G
- Supports the latest PCIe 5.0 I/O and DDR5 memory
Website:https://www.marvell.com/

Napatech : NT200A02 SmartNIC – FPGA
Napatech is a provider of programmable FPGA-based SmartNIC solutions serving global telecom, cloud, enterprise, cybersecurity, and financial applications. Napatech SmartNICs include 1 GbE, 10 GbE, 25 GbE, 40 GbE, and 100 GbE options with software support to offload computationally intensive networking and security processing from the server CPU.

Napatech NT200A02 SmartNIC is based on Xilinx’s powerful UltraScale+ VU5P FPGA architecture and supports 2×1/10G, 8x10G, 2×10/25G, 4×10/25G, 2x40G, 2x100G applications. NT200A02 SmartNIC supports GTP, IP-in-IP, NVGRE, VxLAN, and other tunneling protocols.
The NT200A02 SmartNIC can also delete duplicate packets, fragment packets, and filter packets to reduce the amount of data, thereby offloading server applications. Stateful stream processing with support for 140 million streams enables CPU-intensive applications to intelligently and accurately choose which streams to process and which streams to ignore. Maintain all flow records and report to the application.
Website:https://www.napatech.com/

Netronome : Agilio Series
Netronome is a company specializing in network stream processor acceleration semiconductors, its Agilio series SmartNICs provide the performance and programmability required by cloud operators and service providers without consuming a large number of CPU cores.
- Netronome Agilio CX SmartNIC adopts small form factor PCIe form factor and 10, 25, 40 and 50GbE throughput, offloads entire virtual switch datapath processing for network functions such as overlay, security, load balancing and telemetry.
- The Agilio FX 10GbE SmartNIC combines the company’s NFP with a quad-core general purpose Arm v8, providing the flexibility to address server and network scalability challenges.
- Agilio LX 40/100GbE SmartNICs are designed for x86 server-based virtualized and non-virtualized business nodes and WAN gateways. The solution provides significant scalability for network functions used in mobile core, security, load balancing, and gateway applications.
Website:https://www.netronome.com/
Nvidia: BlueField DPU – SoC: ARM+ASIC+Dedicated Accelerator/GPU Dedicated Accelerator
Nvidia, is an American multinational technology company incorporated in Delaware and based in Santa Clara, California. In 1999, Nvidia defined the GPU, greatly boosting the PC gaming market, redefining modern computer graphics technology. In April 2020, NVIDIA officially announced that it had completed the acquisition of Mellanox, with a product layout covering CPU, GPU, and DPU.
NVIDIA BlueField DPU brings innovation to the modern data center. By offloading, accelerating, and segregating a wide range of advanced networking, storage, and security services, BlueField DPUs provide a securely accelerated infrastructure for a variety of workloads in environments such as cloud, data center or edge computing. BlueField DPUs combine powerful computing power, full on-chip infrastructure programmability, and high-performance networking to support demanding workloads.
- Edge-to-Center Security: BlueField DPU supports a zero-trust comprehensive security architecture covering data center and edge computing.
- Elastic storage for expanding workloads: With support for NVMe over Fabric (NVME-OF), GPU Direct storage, encryption, elastic storage, data integrity, decompression, and deduplication. BlueField provides high-performance storage access solutions that enable ultra-low latency for remote storage.
- High-Performance and Efficient Networking: BlueField is a Powerful Data Center Service Accelerator that provides Ethernet or InfiniBand connection speeds of up to 400 Gb/s for both traditional and modern GPU-accelerated applications while freeing up host CPU cores to run applications outside of infrastructure tasks.
- Software-defined Infrastructure: NVIDIA DOCA™ Software Development Suite (SDK) enables developers to easily create high-performance, software-defined, cloud-native DPU acceleration services using industry-standard APIs.

- NVIDIA BlueField-3 is the first 400Gb/s DPU to process software-defined networking, storage, and cybersecurity at wire speed. BlueField-3 combines powerful computing power, high-speed networking, and extensive programmability to provide a software-defined, hardware-accelerated solution for demanding workloads. From accelerated AI computing to hybrid cloud, to cloud-native supercomputing and 5G wireless networking, BlueField-3 redefines the possibilities.
Website:https://www.nvidia.com/en-us/
Silicom :N5010 , N5110A, P425G2SNxlAONIC – FPGA
Silicom is an industry-leading provider of high-performance networking and data infrastructure solutions.

- Silicom FPGA SmartNIC N5010: A hardware programmable 4x100G FPGA SmartNIC that integrates an Intel Stratix 10 DX FPGA and an Intel® Ethernet 800 Series Adapter optimized for packet processing and traffic management. The N5010 series is equipped with 8GB HBM2, along with DDR4 memory and quad-channel QSFP28, supporting 4x 100 Gigabit/s up to 500Gbps.
- The Silicom N5110A PCIe SmartNIC is a full-length PCIe single-slot card that provides extreme computing performance and wire-speed network switching with the onboard Intel Atom P5900 processor and Intel Stratix 10 FPGA.
- Silicom P425G2SNx IAONIC SmartNIC is based on Intel P5700 processor containing 8/16 X86 cores, an integrated packet processor with 25G/100G interface, and Ethernet MAC using Intel® E810. Hardware standard NIC (via PCIe V4) ports with two 25 GB ports or one 100 GB port, enable offloading full infrastructure workloads from the host while still working at wire speed.
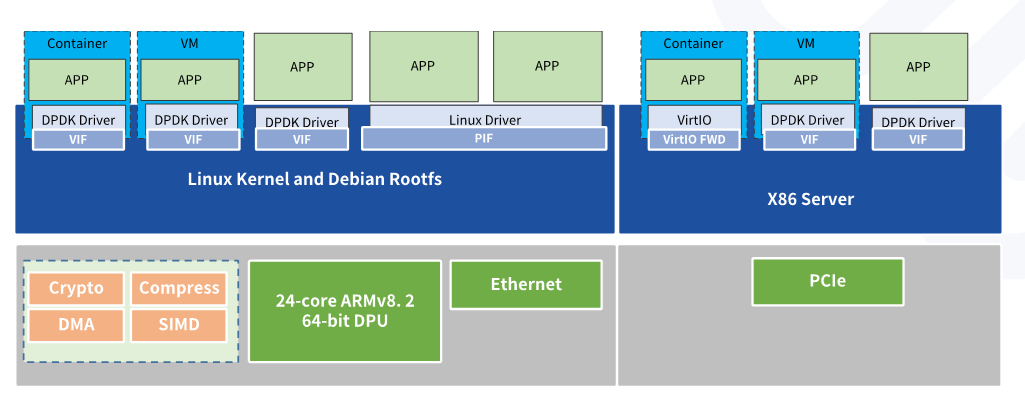
Based on the Marvell octeon cn96xx chip, Asterfusion ET3000A is 48 core high performance DPU appliance.
It can be deployed into a variety of network scenarios, such as edge computing, NFV offload, network security devices such as security gateways, network monitoring; Layer 3/edge Routers and switches, Software Defined Networks (SDN), Network Function Virtualization (NFV), Artificial Intelligence (AI), SSL/IPsec offload processing, LTE/ IoT/Fog/edge gateways, SD-WAN, 5G UPF application, intrusion protection system(IPS)
Website:https://cloudswit.ch/
DPU Vendors & Product Lines Summarize
Reference :
- https://www.sdnlab.com/25836.html
- https://en.wikipedia.org/wiki/Data_processing_unit
- Bhageshpur, Kiran (2016-10-06). “The Emergence Of Data-Centric Computing”. The Next Platform. Retrieved 2021-05-29.
- ServeTheHome (2021-05-30). “DPU vs SmarNICs vs Exotic FPGAs”. ServeTheHome. Retrieved 2022-01-03.






