Table of Contents
The AI Revolution: Transforming Our World
Artificial Intelligence (AI) is not just a buzzword; it’s a groundbreaking force reshaping industries and our everyday lives. From healthcare to finance, and entertainment to education, AI is the catalyst for change, driving innovation and efficiency like never before. Imagine a world where real-time gaming, virtual reality, and the metaverse aren’t just futuristic concepts but integral parts of our daily interactions. This is the reality AI is crafting, fundamentally altering how networking, computing, and data storage systems operate.
Asterfusion: Leading the Charge in AI Networking Solutions
In this rapidly evolving landscape, Asterfusion stands out as a pioneer, offering cutting-edge networking solutions tailored for AI and machine learning workloads. As AI applications grow exponentially, the demand for robust, energy-efficient interconnects becomes critical. Asterfusion’s IP/Ethernet solutions are designed to meet these demands, ensuring seamless integration and optimal performance across vast networks of processors and storage systems.
Modern AI applications require networks that are not only fast but also reliable and scalable. We’re talking about interconnecting hundreds or thousands of accelerators at lightning speeds of 100Gbps, 200Gbps, and even up to 800Gbps. Asterfusion’s switches are engineered to deliver this high-bandwidth, low-latency performance, making them the go-to choice for building next-generation network fabrics.

Asterfusion & The Ultra Ethernet Consortium
In March 2024, Asterfusion took a significant step forward by joining the Ultra Ethernet Consortium (UEC), a collaborative effort led by the Linux Foundation and some of the world’s top tech companies. The UEC aims to revolutionize Ethernet technology, breaking through traditional performance bottlenecks to make it suitable for AI and high-performance computing networks.
As a full member, Asterfusion is at the forefront of developing the next-generation communication stack architecture, ensuring Ethernet’s continued relevance and efficiency in the AI era.
Asterfusion AI Switches Portfolio
-
 800GbE Switch with 64x OSFP Ports, 51.2Tbps, Enterprise SONiC Ready
800GbE Switch with 64x OSFP Ports, 51.2Tbps, Enterprise SONiC Ready -
 64-Port 200G QSFP56 Data Center Switch Enterprise SONiC Ready
64-Port 200G QSFP56 Data Center Switch Enterprise SONiC Ready -
 32-Port 400G QSFP-DD Data Center Switch for AI/ML Enterprise SONiC Ready
32-Port 400G QSFP-DD Data Center Switch for AI/ML Enterprise SONiC Ready -
 64-Port 100G QSFP28 Data Center Switch Enterprise SONiC Ready
64-Port 100G QSFP28 Data Center Switch Enterprise SONiC Ready -
 32-Port 100G QSFP28 Low Latency Data Center Switch, Enterprise SONiC Ready
32-Port 100G QSFP28 Low Latency Data Center Switch, Enterprise SONiC Ready
Asterfusion: Your Ultimate Solution for AI Networking
When it comes to AI networking, Asterfusion stands out with a suite of advantages designed to deliver unmatched performance and flexibility. Let’s dive into why Asterfusion is at the forefront of this transformative technology.
Unmatched Platform Flexibility
Asterfusion offers a versatile range of box platforms, from compact 1U units to robust 2U setups. These can be deployed individually for smaller clusters or combined to support expansive topologies of over 100,000 accelerators. The CX-N series is particularly noteworthy, featuring a vast array of ports including 800G, 400G, 200G, and 100G, with capacities ranging from 2T to an astounding 51.2Tbps. Their latest 800G AI switch is a game-changer, boasting ultra-large capacity with 64 x 800G Ethernet ports with a total switching capacity of 51.2T, having the world’s fastest switch with port-to-port latency under 560ns.
Advanced Networking Capabilities with AsterNOS
At the heart of Asterfusion’s offerings is the self-developed Asterfusion Enterprise SONiC Distribution – AsterNOS. This is the cornerstone of cloud network solutions for next-gen data centers and high-performance AI networks. AsterNOS is equipped with features that ensure high reliability, quality, and performance, delivering lossless, high-bandwidth, low-latency networks. It supports ROCEv2 and EVPN-multihoming, crucial for implementing low-latency, lossless networks and running high-value workloads efficiently.
Industry-Leading Low Latency with CX-N Ultra Low Latency Switches
The Asterfusion CX-N series is engineered for those who demand the best in low-latency switching capabilities. Leveraging Marvell Teralynx 7 and Marvell Teralynx 10 technologies, it offers unparalleled performance across various applications, achieving latencies as low as ~400ns. Its extensive on-chip packet cache, over 200MB in capacity, drastically reduces the storage and forwarding latency of RoCE traffic during collective communications, making it ideal for cutting-edge AI applications.

Promoting an Open Ecosystem
Asterfusion is committed to fostering an open ecosystem for AI networks, collaborating with industry leaders to ensure flexibility and interoperability. With a broad Ethernet-based ecosystem that includes multiple system vendors, silicon providers, interconnects, and optics, Asterfusion empowers customers with complete freedom of choice. This open ecosystem supports REST API integration, enabling seamless collaboration with computing devices and facilitating automatic GPU cluster deployment.
Efficient and Flexible Ethernet-Based AI Networks
Asterfusion’s Ethernet-based networks are designed for interoperability, streamlining efficient and flexible designs that eliminate compatibility issues. This versatility allows Asterfusion’s solutions to be consistently deployed across general-purpose compute, data center, storage, and AI networks, avoiding the pitfalls of inter-domain gateways and pipeline bottlenecks.
Innovative Technologies for Optimal Performance
- INNOFLEX Programmable Forwarding Engine: This innovative engine dynamically adjusts the forwarding process in real-time based on business needs and network status, minimizing packet loss from congestion and failures.
- FLASHLIGHT Traffic Analysis Engine: It measures packet delay and round-trip time in real-time, utilizing intelligent CPU analysis for adaptive routing and congestion control.
- High-Precision Time Synchronization: With 10 nanosecond PTP/SyncE synchronization, Asterfusion ensures synchronous computing across all GPUs, enhancing collaborative processing capabilities.
- Load-aware Balancing: The system’s load-aware per flowlet/packet balancing prevents congestion, ensuring efficient bandwidth utilization.
- Active Queue Management: active queue management, utilizing Explicit Congestion Notification (ECN), proactively avoids traffic congestion, maintaining smooth network operations
Asterfusion AI Switches Offers Forward-compatible Products with UEC Standard.
As the Ultra Ethernet Consortium (UEC) completes its expansion to improve Ethernet for AI workloads, Asterfusion is building products that will be ready for the future. The Asterfusion CX-N AI data centre switch portfolio is the definitive choice for AI networks, leveraging standards-based Ethernet systems to provide a comprehensive range of intelligent features. These features include dynamic load balancing, congestion control, and reliable packet delivery to all ROCE-enabled network adapters. As soon as the UEC specification is finalised, the Asterfusion AI platform will be upgradeable to comply with it.
Embrace the Future of AI/ML Data Center Network Infrastructure with Asterfusion AI Switches
RoCEv2 AI Solution with NVIDIA DGX SuperPOD
In the world of AI and machine learning, the NVIDIA DGX SuperPOD™ with NVIDIA DGX™ H100 systems represents the pinnacle of data center architecture. Asterfusion is pioneering a new approach, harnessing the power of RoCEv2-enabled 100G-800G Ethernet switches to build DGX H100-based superPODs.
This innovative solution replaces traditional InfiniBand switches, encompassing compute fabric, storage fabric, and both in-band and out-of-band management networks.
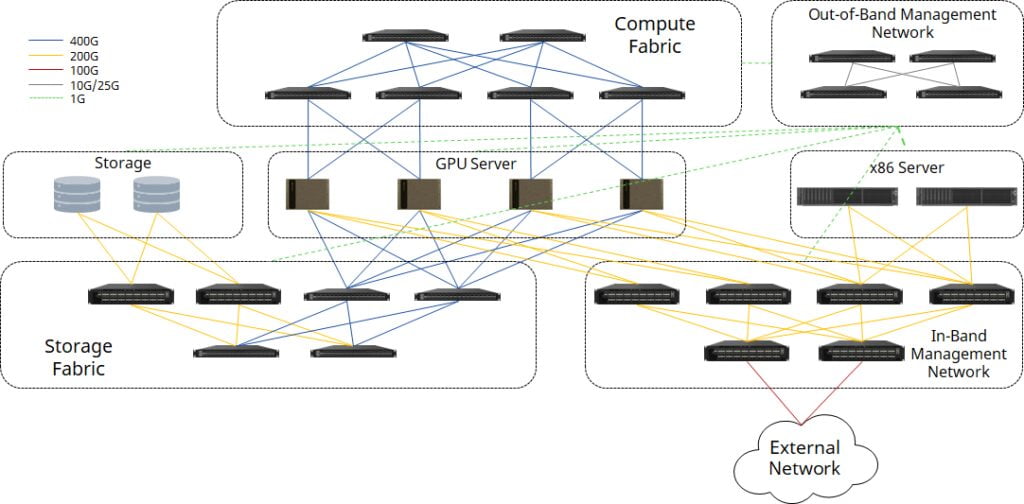
Compute Fabric: Scalability and Efficiency
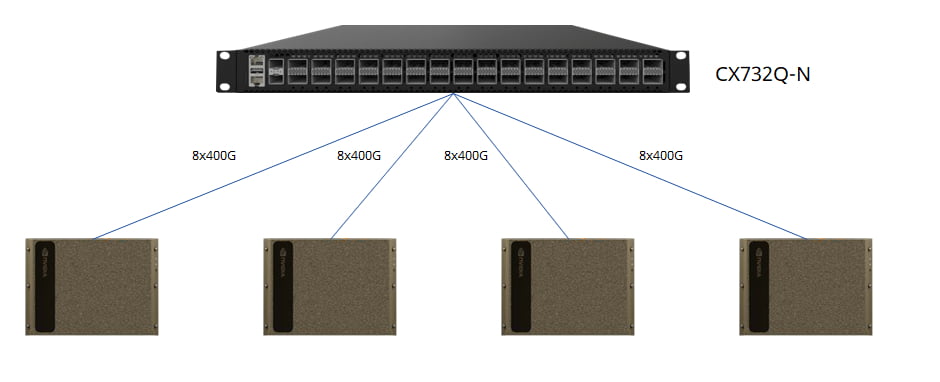
When embarking on a research project or proof of concept, a small-scale cluster is often the ideal starting point. With fewer than four DGX H100 nodes, a single 32x400G switch can connect the entire cluster, utilizing QSFP-DD transceivers on switch ports and OSFP transceivers on ConnectX-7 NICs, linked by MPO-APC cables.
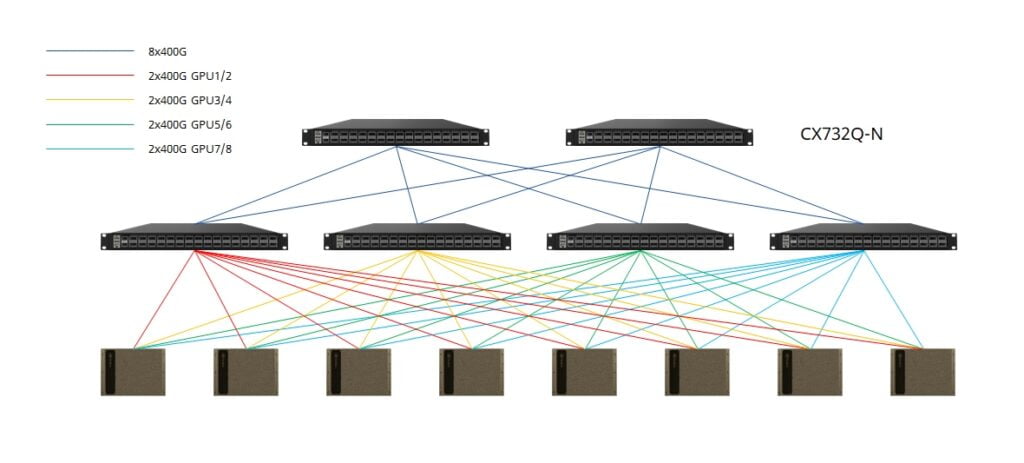
As the number of GPU servers grows to eight, a 2+4 CLOS fabric configuration optimizes rail connectivity, maximizing the efficiency of GPU resources. Spine and leaf switches interconnect via QSFP-DD transceivers with fiber or QSFP-DD AOC/DAC/AEC cables.
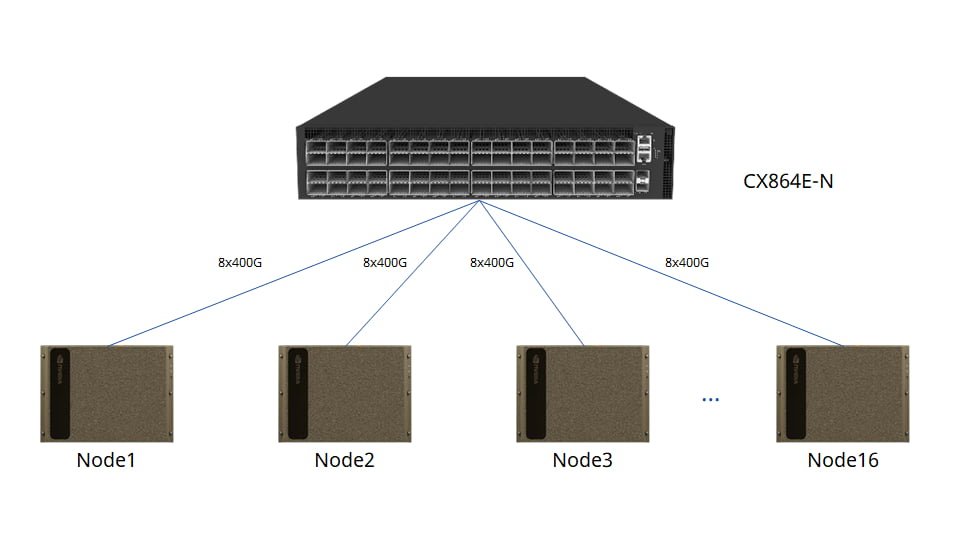
For even greater capacity, the forthcoming CX864E-N switch (51.2Tbps Marvell Teralynx 10 based 64x800G switch, available in 2024Q3) can support up to 16 GPU servers.
Asterfusion’s scalable compute fabric is built upon modular blocks, enabling rapid deployment at multiple scales. Each block comprises a group of GPU servers and 400G switches (such as 16 DGX H100 systems with 8 CX732Q-N switches). Rail-aligned, non-oversubscribed block design ensures optimal compute fabric performance.

A typical 64-node compute fabric leverages a Leaf-Spine architecture, accommodating four blocks.

To further scale the fabric, higher-throughput switches like the CX864E-N can replace spines, expanding the network to a maximum of 16 blocks and 256 nodes.


Storage Fabric: Redundancy and Efficiency
Storage specifications vary by vendor and product. Assuming each node offers 45GB/s read performance via 4x200G interfaces, each DGX H100 node requires 8GB/s read performance (as per NVIDIA documentation), totaling 256GB/s across the cluster (necessitating six storage nodes in this scenario).
While MC-LAG is typically used for redundancy, Asterfusion recommends EVPN Multi-Homing to minimize switch port requirements and enhance storage fabric efficiency.


In-Band Management Network: Seamless Connectivity
The in-band network provides connectivity for both in-cluster services and external services, linking all compute nodes and management nodes (general-purpose x86 servers).

Out-of-Band Management Network: Comprehensive Control
Asterfusion’s 1G/10G/25G enterprise switches, which also support Leaf-Spine architecture, offer robust out-of-band management capabilities, ensuring control over all superPOD components.

Asterfusion’s RoCEv2-enabled Ethernet solution for NVIDIA DGX H100-based superPODs redefines the possibilities for AI and machine learning infrastructure. By offering a scalable, efficient, and highly performant alternative to traditional InfiniBand-based architectures, Asterfusion empowers organizations to unlock the full potential of their AI workloads.



