Table of Contents
Imagine a world where artificial intelligence doesn’t just analyze data, but creates it. Where AI systems generate stunning works of art, craft compelling stories, and even compose music. This isn’t the stuff of science fiction anymore-it’s the reality of generative AI. And it’s transforming the way we think about data centers.
The rise of OpenAI’s ChatGPT and Google’s Bard is just the beginning. The generative AI market is projected to skyrocket to a staggering $126.5 billion by 2031, growing at a mind-boggling 32% per year. At the heart of this revolution are the data centers that power these AI powerhouses. But they’re not your average data centers. They’re specialized AI data center networks, designed from the ground up to meet the unique demands of generative AI.
What is AI Data Center Network?
AI Data Center Network refers to a data center network fabric that supports artificial intelligence (AI). It meets the stringent network scalability, performance, and low latency requirements of AI and machine learning (ML) workloads, especially during the demanding AI training phase.

AI-Specific Data Centers (AIDC):
AI Factory Two different types of data centers are emerging: AI Factory and AI Cloud.
Both types of data centers are tailored to meet the unique needs of AI workloads and are characterized by their reliance on accelerated computing.
AI Factory
AI Factory is designed to handle large-scale algorithm models like large language models (LLMs) and other basic AI models, which serve as the building blocks for more advanced AI systems. To achieve seamless expansion of clusters with thousands of GPUs and efficient resource utilization, a strong high-performance network is imperative.
AI Cloud
AI Cloud extends traditional cloud infrastructure to support large-scale generative AI applications.Generative AI goes beyond traditional AI, creating new content like images, text, and audio based on its training data.To manage an AI Cloud serving thousands of users, you need advanced management tools and network infrastructure to efficiently handle diverse workloads.
Understanding the Impact of AI Workload Patterns on Data Center Networks
As AI technology advances, it’s essential to understand how these powerful workloads influence data center networks. To grasp this impact, we must first delve into the underlying mechanisms of AI processing, which can be broken down into three primary stages: data preparation, training, and inference.
- Data Preparation: Laying the Foundation The journey begins with data preparation, where diverse, complex datasets are collected and organized as input for AI models. These datasets can originate from public sources, user-generated social media content, internal enterprise data, partner data, and even third-party data that’s been purchased.
- Training: Where AI Comes Alive The training stage is where AI truly begins to learn. By feeding massive datasets into AI models, we enable them to develop improved prediction accuracy and generalization capabilities through sophisticated algorithms. This process demands substantial computing resources and time, often leveraging accelerated devices like GPUs or TPUs. As the models analyze intricate patterns and correlations within the data, they gradually refine their predictive powers.
- Inference: Putting Learning into Practice In the final inference phase, the trained AI models are put into action. They receive input data and perform classification or predictive operations, ultimately outputting the AI’s decisions or answers.
The first two stages, data preparation and training, require immense computing resources, often relying on proprietary, high-performance processors like CPUs, GPUs, FPGAs, and custom accelerators. For the inference stage, the data center network connecting all these processing units (as well as servers and storage) must deliver exceptional high bandwidth, ultra-low latency, and guarantee lossless packet transmission. As AI workloads continue to evolve and grow, it’s critical for data center networks to be optimized to meet these demanding requirements, ensuring seamless performance and efficiency.
From Traditional Data Center Evolving to AIDC
Traditional Cloud Data Center obstacles in AI era
While traditional cloud data center network architecture is time-tested and reliable, it struggles to meet the dynamic demands of AI-driven environments. Originally designed to handle external service traffic with a north-south flow focus and an east-west flow as a secondary consideration, it now faces several obstacles:
- High Bandwidth Bottlenecks: The uplink/downlink bandwidth convergence ratio is about 1:3, creating significant traffic jams.
- Significant Latency: Every intra-cloud server interaction must pass through the spine switch, leading to longer forwarding paths and increased delays.
- Limited NIC Bandwidth: With a single physical server boasting only one NIC and a maximum bandwidth of 200 Gbps, overall performance is constrained.
These challenges hinder the efficiency of intelligent computing services. To rise to the occasion, we need to innovate and develop a fresh network architecture that can seamlessly handle the escalating demands of AI. According to Meta, AI workloads spend approximately one-third of their time waiting for network processes. AI is advancing at an unprecedented pace. Models are growing 1,000 times more complex every three years. But our networks are struggling to handle the load. Simply throwing more servers at the problem won’t cut it. We need a fundamentally new approach to network architecture, one designed from the ground up for AI.
Here’s the shocking truth: even though those fancy GPU servers are pricey, half of the actual processing happens on the network. And if that network is slow, it doesn’t matter how powerful your GPUs are. They’ll just be twiddling their thumbs, wasting money and slowing down your whole operation. That’s why ultra-fast, lossless networks are no longer a nice-to-have. They’re a must-have. But the challenges don’t stop there. AI workloads require networks to be scalable in ways traditional ones aren’t. We’re talking the ability to expand horizontally and vertically, handling massive surges of packets, intelligently redirecting traffic… it’s a tall order. And the network operating system at the heart of it all needs to be up to the task.
What does an AI-optimized Network Look Like?
Firstly it’s all about bandwidth. While high-performance computing is laser-focused on minimizing latency, AI is different. We need to move massive amounts of data fast. In fact, AI inference workloads can generate 5 times more traffic than training ones. And the backend network needs to juggle thousands of jobs at once. In contrast to HPC networks, which are built for many small workloads, AI networks have to handle a smaller number of truly enormous ones. It’s a different beast altogether. And our networks need to evolve to tame it.
Latency is the enemy: For AI workloads, every millisecond matters. Delays mean scalability issues, timeouts, and a poor user experience. In some cases, the consequences can be severe – think costly manufacturing mistakes or even safety risks.
Packet loss equals disaster: AI applications can’t tolerate packet loss. It introduces latency and unpredictability, rendering networks unusable for these sensitive workloads. Lossless networks are non-negotiable for AI.
Density creates complexity: As we deploy dense GPU racks for AI computing, traditional networking approaches break down. Cabling becomes a nightmare, and switch port density needs skyrocket – think four times the usual amount. By 2027, up to 20% of switch ports will serve AI servers alone. Power and cooling systems must adapt, and micro data centers may be the answer. But this distributed model puts immense pressure on networks to deliver high-performance, scalable connectivity.
Manual management is obsolete: AI networks are complex. They require fine-tuned performance and reliability. Command lines and disjointed monitoring tools are no match for these sophisticated environments. It’s time for automated network orchestration platforms that deliver insights and control from day one.
The AI Data Center Network Revolution: InfiniBand vs. Ultra Ethernet
For years, InfiniBand, a lightning-fast, proprietary network technology, was the undisputed champion. Its blistering speed and razor-sharp efficiency made it the go-to choice for powering the complex communication between servers and storage systems that fuels AI innovation.
But in recent years, a challenger has emerged from the shadows. Ethernet, once considered the underdog, is gaining ground at an astonishing pace. The calls for Ethernet to dethrone InfiniBand are growing louder by the day.
Why the sudden shift? It all comes down to one word: openness. While InfiniBand is proprietary, Ethernet boasts an open ecosystem that plays nice with a wide variety of graphics processing units (GPUs). Plus, Ethernet has a massive pool of skilled professionals who know it inside and out, along with a wealth of management tools at your disposal. And let’s be real – Ethernet’s price tag is a fraction of InfiniBand’s.
The momentum behind Ethernet reached a fever pitch with the launch of the Ultra Ethernet Consortium (UEC). This powerhouse organization, backed by the Linux Foundation, is on a mission to supercharge Ethernet with cutting-edge features that leave InfiniBand in the dust. Think high-performance, distributed, and lossless transport layers optimized specifically for HPC and AI workloads. The gauntlet has been thrown.

Today, Ethernet is more than just a contender – it’s an open-source powerhouse that’s capturing the attention of AI data center networks worldwide. It’s not a question of if Ethernet will become mainstream, but when. The revolution is here, and InfiniBand is running out of time.
Contrast of Infiniband and ROCEv2 Technology
| InfiniBand | RoCE | |
| Port-to-Port Delay | About 130 ns | About 400 ns |
| Flow Control | Utilizes a credit-based signaling mechanism to avoid buffer overflow and packet loss, ensuring lossless HCA-to-HCA communication. | Relies on lossless Ethernet, typically configured via Ethernet flow control or priority flow control (PFC) for reaching performance characteristics similar to InfiniBand |
| Forwarding Mode | Forwarding based on Local ID | IP-based Forwarding |
| Scalability | High. A single subnet of Infiniband can support tens of thousands of nodes. It also provides a relatively simple and scalable architecture to create virtually unlimited cluster sizes with Infiniband routers. | High. RoCEv2 is based on UDP and has good scalability across network segments, so it is a solution adopted on a large scale. RoCE supports dynamic creation and adjustment of network topology, making it adaptable to the needs of data centers of different sizes. |
| Reliability | Implemented through InfiniBand proprietary protocol combined with adaptive routing | IP-based ECMP mechanism is realized. In addition, RoCE supports error correction and retransmission mechanisms, further improving the reliability of data transmission. |
| Cost | Very expensive: servers require dedicated IB NICs, dedicated IB switches to build a dedicated network, generally five to ten times the cost of ordinary network equipment, and are only considered for use in high profile environments such as finance and futures trading | Lower cost Excellent price/performance ratio Some of the white box manufacturers’ ROCE v2 -ready data center switches are about half or even a third of the price of an IB switch |
For more: https://cloudswit.ch/blogs/how-to-choose-from-infiniband-and-roce-for-aigc/
UEC Transport: Revolutionizing RDMA on Ethernet for AI and HPC
The pursuit of optimized performance for AI and High-Performance Computing (HPC) workloads has driven the development of the UEC transport protocol. Spearheaded by the Ultra Ethernet Consortium (UEC), this transformative technology is reshaping the landscape of Remote Direct Memory Access (RDMA) operations on Ethernet.
RDMA (Remote Direct Memory Access) technology comes to mind as a game-changer. Imagine a world where your CPU is freed from mundane data handling tasks, allowing for seamless memory sharing, boosting data throughput, and slashing response times. RDMA is not just a high-efficiency solution for distributed systems; it’s the secret sauce that transforms AI data center networks. With RDMA, we unlock microsecond-level low latency, soaring throughput, and near-zero packet loss, enabling a new era of network performance and reliability.
A New Era in Ethernet Optimization
UEC’s mission is clear: unlock the full potential of Ethernet to meet the demanding requirements of AI and HPC applications. By innovating across the physical, link, transport, and software layers, UEC is pushing the boundaries of Ethernet forwarding performance. The Ultra Ethernet Transport Working Group (UET) has implemented groundbreaking enhancements to maximize network utilization and minimize tail latency – the key to reducing AI and HPC job completion times.
Key Innovations Powering UEC Transport
- Multipath and Message Spreading: Break free from the constraints of traditional spanning tree-based Ethernet networks. UET’s multipath and message spreading technology enables packets to leverage all available paths to the destination simultaneously, ensuring optimal network resource utilization without the need for complex load balancing algorithms.
- Flexible Delivery Order: Streamline packet transmission with UET’s flexible delivery order capabilities. This feature is paramount for high-throughput collective operations in AI workloads, such as All-Reduce and All-to-All.
- Modern Congestion Control: UET’s cutting-edge congestion control algorithms intelligently manage network congestion by considering multiple link conditions between sender and receiver. The result? More efficient data transmission and minimized network bottlenecks.
- End-to-End Telemetry: Gain real-time insights into network congestion with UET’s end-to-end telemetry schemes. These capabilities enable swift congestion control responses by providing the sender with critical information from the network source.
UEC Transport: Powering the Future of AI and HPC Networking
By retaining the IP protocol while introducing multipath support, enhancing packet sorting and congestion control, and providing a simpler, more efficient RDMA interconnect, UET is poised to meet the escalating demands of AI and HPC workloads. As a proud member of the UEC, Asterfusion is committed to shaping the future of Ethernet communication stacks and driving the adoption of this transformative technology in AI and HPC. Together, we’re building a more efficient, powerful networking ecosystem for the challenges ahead.
Embrace the Future of AI/ML Network Infrastructure with Asterfusion
RoCEv2 AI Solution with NVIDIA DGX SuperPOD
In the world of AI and machine learning, the NVIDIA DGX SuperPOD™ with NVIDIA DGX™ H100 systems represents the pinnacle of data center architecture. Asterfusion is pioneering a new approach, harnessing the power of RoCEv2-enabled 100G-800G Ethernet switches to build DGX H100-based superPODs.
This innovative solution replaces traditional InfiniBand switches, encompassing compute fabric, storage fabric, and both in-band and out-of-band management networks.
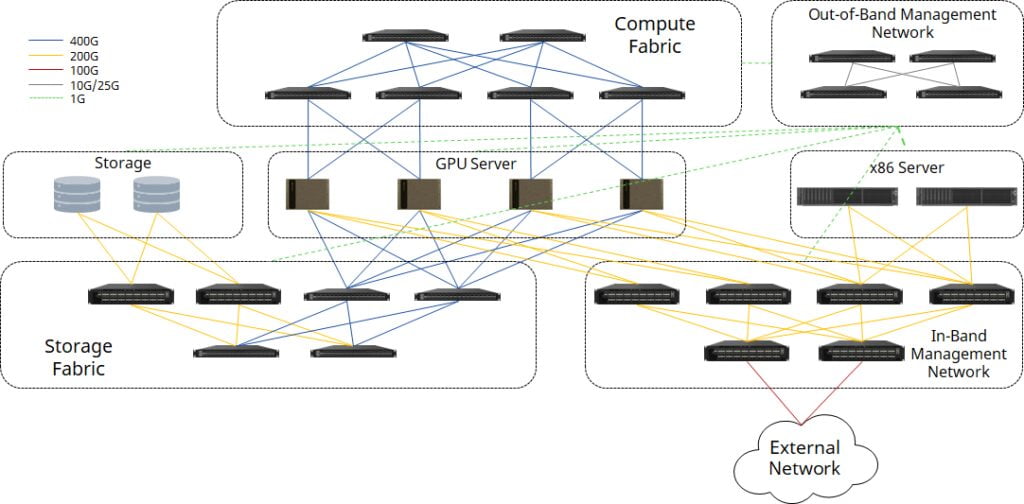
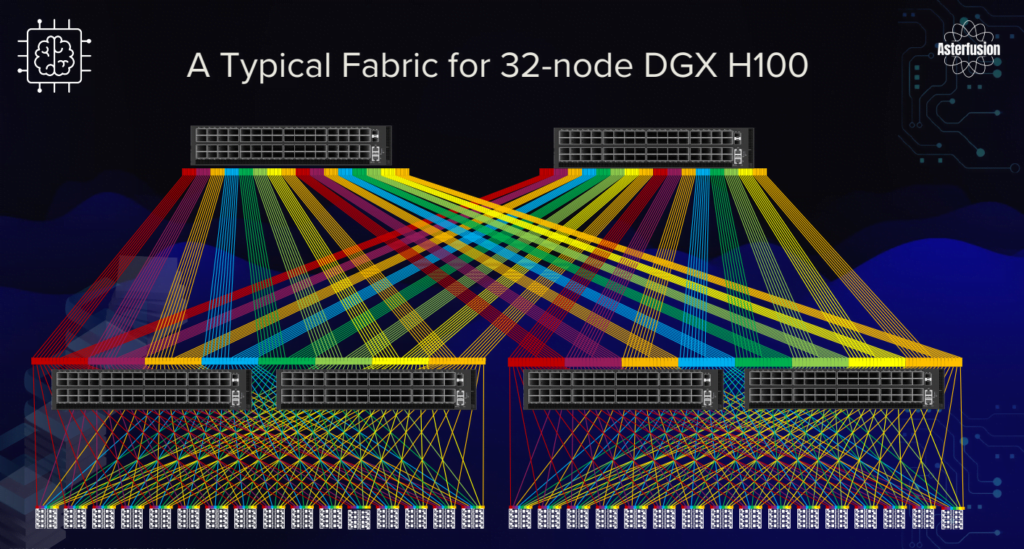
Compute Fabric: Scalability and Efficiency
When embarking on a research project or proof of concept, a small-scale cluster is often the ideal starting point. With fewer than four DGX H100 nodes, a single 32x400G switch can connect the entire cluster, utilizing QSFP-DD transceivers on switch ports and OSFP transceivers on ConnectX-7 NICs, linked by MPO-APC cables.
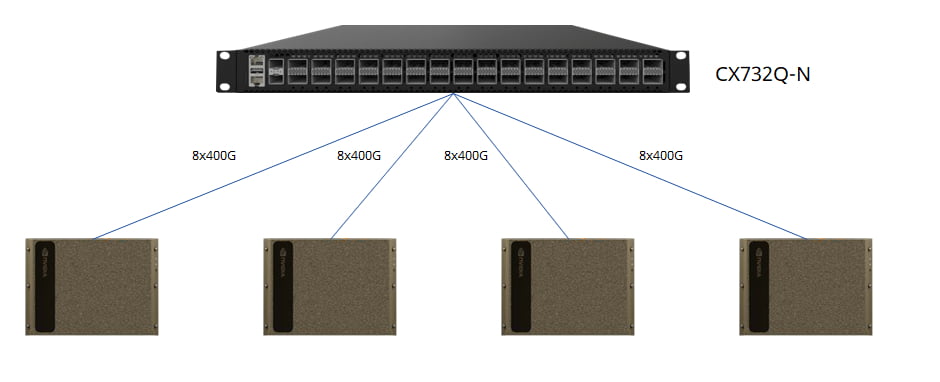
As the number of GPU servers grows to eight, a 2+4 CLOS fabric configuration optimizes rail connectivity, maximizing the efficiency of GPU resources. Spine and leaf switches interconnect via QSFP-DD transceivers with fiber or QSFP-DD AOC/DAC/AEC cables.
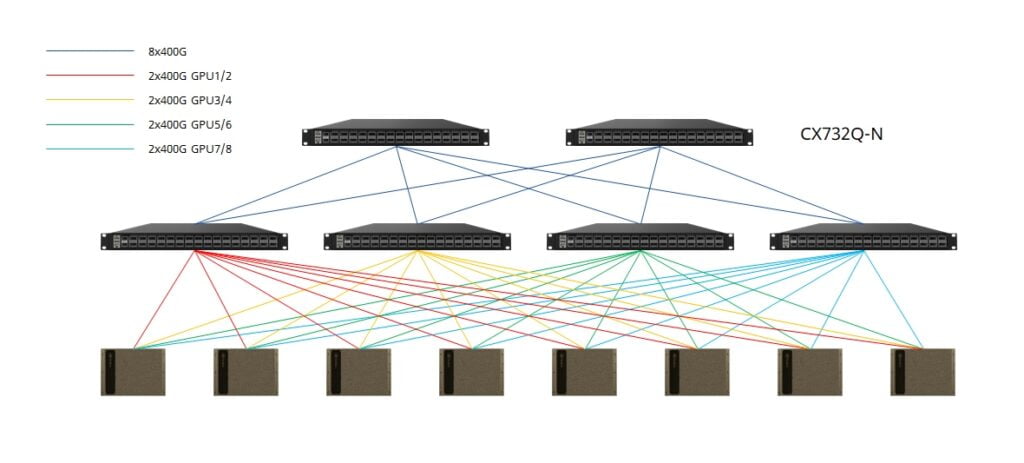
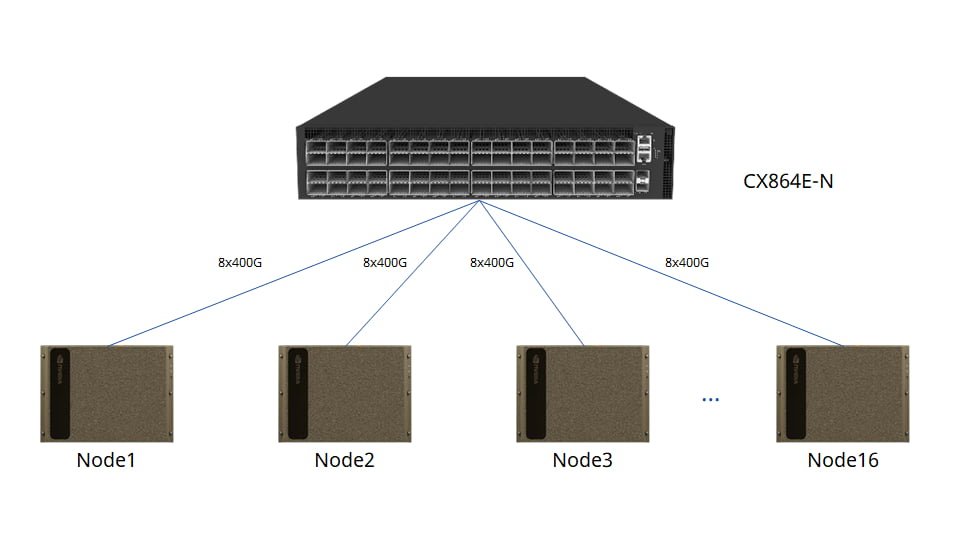
For even greater capacity, the forthcoming CX864E-N switch (51.2Tbps Marvell Teralynx 10 based 64x800G switch, available in 2024Q3) can support up to 16 GPU servers.
Asterfusion’s scalable compute fabric is built upon modular blocks, enabling rapid deployment at multiple scales. Each block comprises a group of GPU servers and 400G switches (such as 16 DGX H100 systems with 8 CX732Q-N switches). Rail-aligned, non-oversubscribed block design ensures optimal compute fabric performance.

A typical 64-node compute fabric leverages a Leaf-Spine architecture, accommodating four blocks.

To further scale the fabric, higher-throughput switches like the CX864E-N can replace spines, expanding the network to a maximum of 16 blocks and 256 nodes.


Storage Fabric: Redundancy and Efficiency
Storage specifications vary by vendor and product. Assuming each node offers 45GB/s read performance via 4x200G interfaces, each DGX H100 node requires 8GB/s read performance (as per NVIDIA documentation), totaling 256GB/s across the cluster (necessitating six storage nodes in this scenario).
While MC-LAG is typically used for redundancy, Asterfusion recommends EVPN Multi-Homing to minimize switch port requirements and enhance storage fabric efficiency.


In-Band Management Network: Seamless Connectivity
The in-band network provides connectivity for both in-cluster services and external services, linking all compute nodes and management nodes (general-purpose x86 servers).

Out-of-Band Management Network: Comprehensive Control
Asterfusion’s 1G/10G/25G enterprise switches, which also support Leaf-Spine architecture, offer robust out-of-band management capabilities, ensuring control over all superPOD components.

Embrace the Future of AI/ML Network Infrastructure with Asterfusion
Asterfusion’s RoCEv2-enabled Ethernet solution for NVIDIA DGX H100-based superPODs redefines the possibilities for AI and machine learning infrastructure. By offering a scalable, efficient, and highly performant alternative to traditional InfiniBand-based architectures, Asterfusion empowers organizations to unlock the full potential of their AI workloads.
Related products:






Reference:
1.AIGC Development Trend Report 2023 (Tencent Research Institute)
2.Weiyang Wang, et al. (2023)How to Build Low-cost Networks for Large Language Models (without Sacrificing Performance)[https://arxiv.org/abs/2307.12169]
3..Jingfeng,Y &Hongye,J ( 26 Apr 2023) Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond https://arxiv.org/abs/2304.13712



