Table of Contents
01. Microsoft’s Billion-Dollar Investment in OpenAI, Azure’s Supercomputer Upgrade, and the Role of Ultra-Low-Latency Network
In 2019, Microsoft pledged to invest a whopping $1 billion in OpenAI and committed to constructing an enormous supercomputer for the cutting-edge AI startup.
Not long ago, Microsoft unveiled details about this exceptionally costly supercomputer and Azure’s impressive upgrade through two articles on their official blog. Scott Guthrie, Microsoft’s Vice President of Cloud Computing and AI, revealed that the company dedicated hundreds of millions of dollars to this ambitious project which combined the power of tens of thousands of Nvidia A100 GPUs with the Azure cloud computing platform.

Undeniably, high-performance computing power is vital for deep learning models like ChatGPT.
However, it is common for people to underestimate the significance of network transmission in accelerating AI training. Particularly during large-scale cluster distributed training, the network plays a crucial role. To train expansive language models effectively, a high-throughput, low-latency network ensures that powerful GPUs can seamlessly collaborate and handle the immense computing workload.
We can also see from Azure’s infrastructure upgrades for “generative AI” that network interconnection capabilities account for a large proportion of it. Microsoft introduced the ND H100 v5 virtual machine, which supports on-demand sizes ranging from eight to thousands of NVIDIA H100 GPUs interconnected by an NVIDIA Quantum-2 InfiniBand network.
Customers will see significantly improved performance of AI models compared to the previous generation ND A100 v4 VM, these innovations include:
• Eight NVIDIA H100 Tensor Core GPUs interconnected via next-generation NVSwitch and NVLink 4.0
• 400 Gb/s NVIDIA Quantum-2 CX7 InfiniBand per GPU and 3.2Tb/s non-blocking fat-tree networking per virtual machine
• NVSwitch and NVLink 4.0 with 3.6TB/s bi-directional bandwidth between 8 local GPUs per virtual machine
• 4th generation Intel Xeon Scalable processors
• PCIE Gen5 to GPU interconnect with 64GB/s bandwidth per GPU
• 16-channel 4800MHz DDR5 DIMM
02. Is InfiniBand the Ultimate Solution for Ultra-Low Latency Networks?
However, the current IB technology comes with its fair share of challenges. Firstly, the market for IB technology is cornered by a limited number of suppliers, inconveniencing users. Secondly, excessively long supply cycles for IB switches may negatively affect the timely implementation of business projects.
Additionally, during regular operation and maintenance phases, resolving issues in the IB network largely relies on original manufacturers, and the efficiency of addressing these challenges depends on their after-sales response times.
03. Feasibility of cost effective ROCEv2-based low latency switch replacing InfiniBand Switch
what is ROCE
AI computing cluster networks on a vast scale, such as ChatGPT, often involve thousands of GPU cards. As AI large-scale model training has inherent requirements, there’s minimal room for optimizing costs on the computing power side. However, if an alternative solution with comparable performance to InfiniBand can be found for the networking aspect—thus reducing initial investments and operational costs—it might be very worth considering.
Since the inception of RoCE (RoCEv2), various technologies, such as RDMA and protocol offloading, once exclusive to IB networks, are now applicable on Ethernet. This allows optimized Ethernet technology to be deployed effectively not only in AI training back-end networks, but also in areas like scientific supercomputing, real-time cloud services, and high-frequency financial transactions.
As we evaluate the possibility of cost-effective, low-latency switches replacing traditional IB networks, the Ethernet-based three-layer CLOS architecture (spine-leaf) emerges as a more fitting choice for present network requirements. With full-box networking in place, communication between any two servers involves no more than three switches.
Considering network protocols, RoCEv2 outperforms other types of RDMA networks due to its superior performance, low deployment costs, and strong compatibility. However, it’s worth noting that to address traditional Ethernet’s “best effort” feature, switches must support the construction of a zero-loss network with minimal packet loss, reduced latency, and high performance.
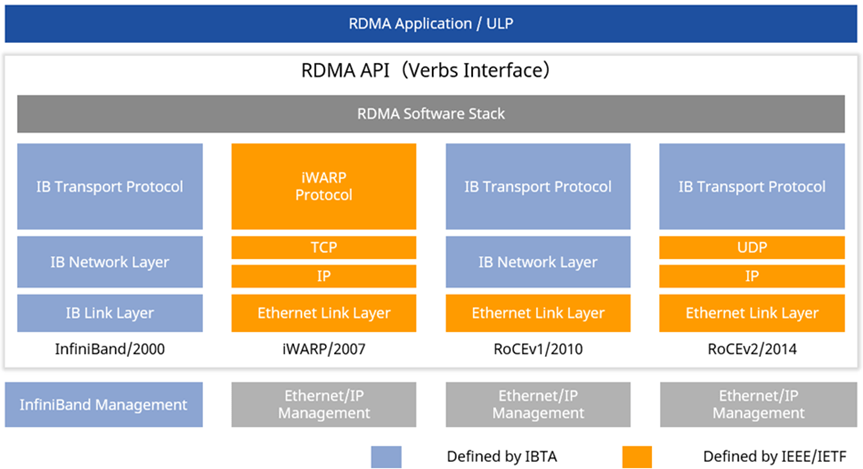
04. Asterfusion CX-N series, an economical & powerful ROCE Data Center switch tailored for ultra-low-latency network
Introducing the Asterfusion CX-N series: state-of-the-art, ultra-low-latency cloud switches engineered explicitly for high-performance Ethernet applications. These versatile switches are meticulously optimized for minimal latency, from the bottom switching chip to the various protocol stacks’ upper layers. With an impressive Port to Port forwarding time of just ~400ns, you can trust Asterfusion to deliver unparalleled speed and efficiency.
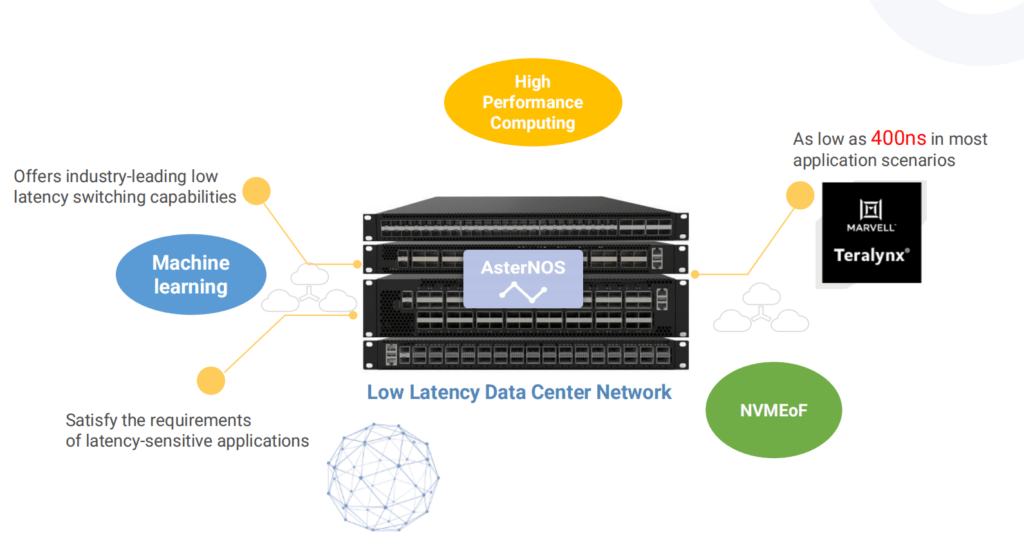
Experience consistent forwarding delay at any rate (10G~400G), and take advantage of advanced data center features such as PFC and ECN. These essential tools help prevent packet loss and alleviate network congestion for a seamless experience.
Numerous clients have compared our CX-N series 32 x 100G Ethernet switches and 32 x 100G IB switches (Mellanox SB7700) in on-site tests, discovering that our Ethernet switches perform remarkably close to IB switches. In some instances, the CX-N series even outperforms its IB counterparts.
In summary, the Asterfusion CX-N series cloud switches lay the foundation for a superior, ultra-low-latency lossless Ethernet network, effortlessly accommodating RoCEv2 to provide an economical solution for those seeking a lightning-fast network.
05. Asterfusion ROCE-based Low Latency Cloud Switch : A Cost -Effective Alternative to InfiniBand
Now, let’s delve into a detailed comparison of Asterfusion’s low latency data center switch & IB switch test outcomes.
Test Results on [HPC Scenario] between Asterfusion’s low latency data center switch and Infiniband switch
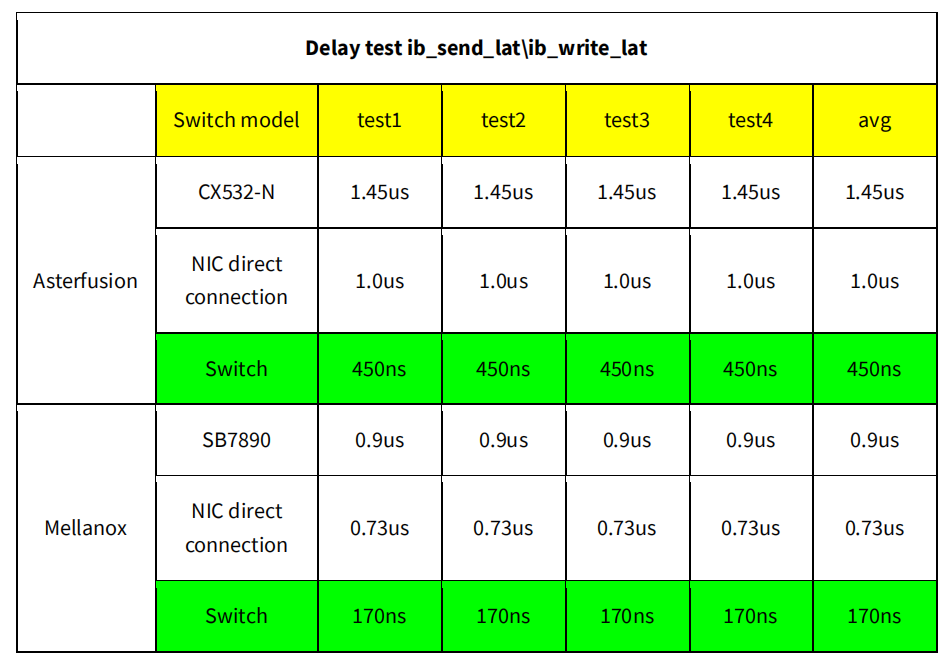


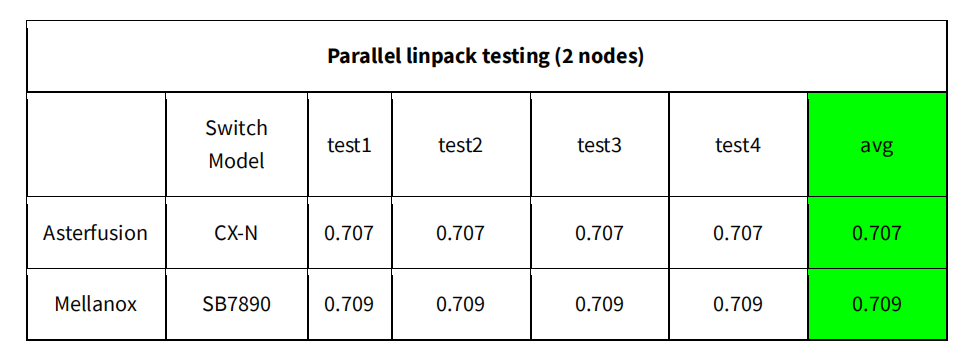
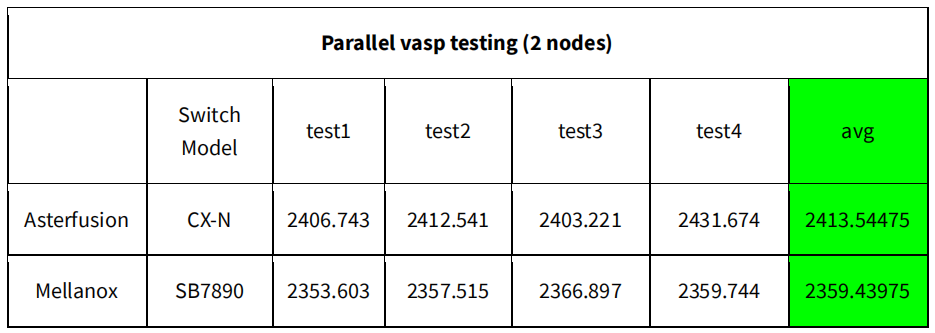
Test Results on [Distributed storage scenario] between Asterfusion’s low latency switch & Infiniband switch
06.Asterfusion RoCEv2 AI Network Solution with NVIDIA DGX SuperPOD
Your AI/ML computing cluster, hungering for speed and reliability, fueled by the power of 800G/400G/200G Ethernet, RoCEv2 technology, and intelligent load balancing. This isn’t just any connection – it’s a high-performance, low-TCO network powerhouse, courtesy of Asterfusion. No matter the size of your cluster, we’ve got you covered with our one-stop solution.
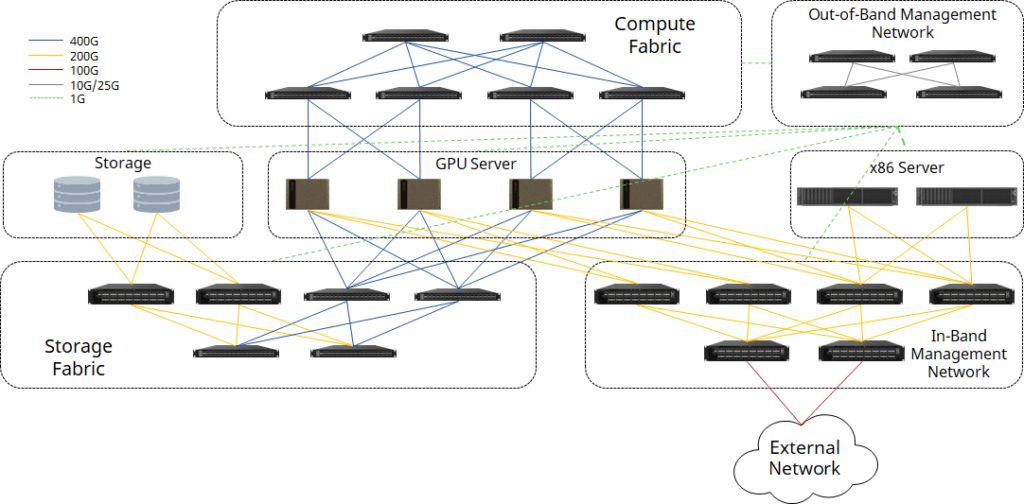
For more about Asterfusion AI network solution :https://cloudswit.ch/solution/rocev2-ai-solution-with-dgx-superpod/
If you are on the lookout for an economical yet powerful low-latency network switch, don’t hesitate to get in touch with Asterfusion today bd@cloudswit.ch
Related Products






