Table of Contents
As AI continues to reshape the world at an electrifying pace, we are reminded of the importance of adaptability. Just as we must continually evolve in response to a transforming world, so too must our data centers, the beating heart of AI infrastructure.
Aurora Supercomputer with Ultra Ethernet.
Let’s take a journey to DuPage County, Illinois. Here, in the hushed halls of the Argonne National Laboratory data center, a monumental project is taking shape. The supercomputer Aurora, poised to become the world’s most powerful, is under construction. An impressive assembly of tech, it will boast 21,248 Intel Xeon Sapphire Rapids CPUs, 63,744 Intel Ponte Vecchio data center GPUs, and 1024 all-flash arrays totaling a whopping 220TB in capacity.

Aurora is already flexing its muscles. It’s achieved an AI performance of over 10.6 exaFLOPS([i]), outpacing its competitors and clinching the top spot in the HPL-MxP benchmark. This puts it well ahead of Nvidia’s SuperPOD system, which sits in seventh place, and it’s already running the Aurora GenAI large-scale model, a 1 trillion parameter powerhouse designed specifically for scientific computing([ii]). This colossal GPU cluster, the largest of its kind in the world, is seamlessly interconnected by a custom-built Super Ethernet system.
What is the Proportion of Ethernet & Infiniband in HPC?
Ethernet, in fact, is spearheading the supercomputing revolution. As of 2024 ([iii]), it’s the preferred choice for 48.5% of the TOP500 supercomputers in terms of performance, outstripping Infiniband, which is used by 39.2%. The top ranks are dominated by Ethernet users. Of the six leading supercomputers, five, including Frontier (world no.1), Aurora (no.2), Fugaku (no.4), LUMI (no.5), and Alps (no.6), all rely on Ethernet.

Unleashing the Power of Ultra Ethernet: A Game-Changer for AI Data Centers
Picture a traditional data center, where the bulk of network traffic flows between computing servers and storage/database servers, with minimal traffic between computing servers. That’s yesterday’s news. The emergence of large-scale models has turned the tables, thrusting the traffic between computing servers, particularly GPU servers, into the limelight.
Considering the sheer scale of these models, soaring past one trillion, and the humongous data sets nearing the 50T mark, innovative techniques like FSDP, tensor parallelism, pipeline parallelism, and MoE have become essential. These techniques catalyze an unparalleled traffic surge between GPU servers, characterized by ultra-high bandwidth needs, ultra-low latency requirements, and the necessity for collective communication.
- Ultra-high bandwidth: Gradient synchronisation requires the transfer of more than 10TB of data.
- Ultra-low latency: Processing a training sample generates more than 100GB of data and must be transmitted within milliseconds.
- Collective communication: All-reduce and all-gather operations between GPU servers generate broadcast traffic and require all nodes to complete the transmission synchronously.
For more about AI data center network :https://cloudswit.ch/blogs/future-of-ai-data-center-network-infrastructure/
AI InfiniBand Switch VS Ultra Ethernet Switch, Which to choose?
Enter the AI InfiniBand Switch and the Ultra Ethernet Switch, two pivotal players in this radical transformation.
InfiniBand, born in 2000 with a focus on the HPC market, took an early lead and became a go-to for many AI data centers. Its low latency, high throughput, and NVIDIA’s acquisition of Mellanox, a major InfiniBand switch manufacturer, all played crucial roles.
But lately, InfiniBand appears to be running out of steam, primarily due to its closed ecosystem. This single-vendor solution comes with a hefty price tag and a slower development pace. It’s an age-old truth: open systems invariably triumph over closed ones.
Ethernet, with its inherent openness, has quickly caught up. RoCEv2-equipped Ethernet switches can now go toe-to-toe with InfiniBand. Notably, the Asterfusion ultra-low latency switch has demonstrated comparable performance to InfiniBand switches during rigorous PoC tests([v]).
Comparison of InfiniBand and RoCEv2 for more: https://cloudswit.ch/blogs/how-to-choose-from-infiniband-and-roce-for-aigc/
Asterfusion CX-N ROCE Ultra-low latency Switch VS InfiniBand Switches Test Data
On-site Test Result: Asterfusion RoCEv2-enabled SONiC Switches Vs. InfiniBand
RoCE Technology for HPC- Test data & Practical Implementations on SONiC switch



Understanding of Ultra Ethernet & UEC
What is Ultra Ethernet
The Ultra Ethernet Consortium (UEC) was officially formed on 19 July 2023 with the goal of going beyond existing Ethernet capabilities such as Remote Direct Memory Access (RDMA) and Converged Ethernet RDMA (RoCE) to provide a high-performance, distributed, lossless transport layer optimised for high performance computing and artificial intelligence, directly targeting competing transport protocol InfiniBand.

Why do we need Ultra Ethernet?
As mentioned earlier, Artificial Intelligence and High Performance Computing bring new challenges to the network, such as the need for greater scale, higher bandwidth density, multipath, rapid response to congestion, and interdependency on the execution of individual data flows (where tail latency is a key consideration).
The design of the UEC specification will fill these gaps and provide the larger scale networking required for these workloads. UEC aims to be a complete communication stack that solves technical problems across multiple protocol layers and provides easy configuration and management capabilities.
How does UEC differ from other existing protocols?
Existing protocols may address some aspects of the above problems (such as initial congestion management), but because they are designed for general purpose networks, they lack features that are critical for AI and HPC, such as multipathing and easy configuration. Existing protocols can also be fragile in these scenarios. Combined with the rich experience of UEC members in large-scale deployments of AI and HPC workloads, the UEC will provide a compelling and comprehensive solution, bringing new hardware and software products that cannot be provided by Ethernet or any other networking technology today!
Continuing with the topic of IB and Ethernet above,in summary, the establishment of the Ultra Ethernet Alliance in 2023 marked a turning point for Ethernet. Ultrar Ethernet, packed with features designed to handle AI traffic challenges, is set to revolutionize data centers.
- Higher bandwidth: 800G is starting to become mainstream. The 1.6T Ethernet interface standard 802.3dj is being formulated and is expected to be released in 2025 ([vi]). The 3.2T Ethernet standard is also on the agenda.
- Global congestion avoidance: The new congestion control and end-to-end telemetry technology will solve the problem of network congestion caused by collective communication, reduce tail latency, significantly improve network throughput, and reduce AI training time.
- True zero packet loss: Through technologies such as multipath, packet spraying and on-demand retransmission, a fast self-healing network is achieved. In the event of minor failures, end-to-end lossless transmission can still be achieved to avoid interruption of AI training tasks.
- Tight time synchronisation: By providing 10ns clock synchronisation through PTP, SyncE and other technologies, GPU clusters can achieve fully synchronised parallel computing, eliminating expensive resource waste caused by waiting between GPUs.
- Ultra-large scale networking: Based on Ethernet’s inherent broadcast characteristics and flexible topology networking capabilities, Super Ethernet will achieve the interconnection of more than 100,000 GPUs, supporting the next generation of large-scale models with a scale of 10 trillion parameters.
In the wake of its upgrade to Ultra Ethernet, there’s no doubt that Ethernet is on the brink of a new era of explosive growth.
Stepping into the Future: The Journey from Ethernet to Ultra Ethernet
The dawn of AI-powered data centers rests on the evolution of Ethernet switches. Just like the foundation of a towering skyscraper, it all begins from the ground up.Ethernet has a rich history. Its inception dates back to May 1973, a time when the first traces of Ethernet technology began to emerge. Since then, it has continuously evolved, keeping pace with the rapid changes in the computing world. This adaptability has cemented Ethernet as the most widely used network technology globally.Ethernet switches have gone through five significant transformations since 1973:
- LAN switches: Ethernet’s openness, large bandwidth, and cost-efficiency allowed it to dominate campus networks.
- Metropolitan area network switches: Upgrading to L3 enabled Ethernet to achieve large-scale networking, expanding its reach citywide.
- Carrier switches: After enhancing reliability, QoS, and security features, Ethernet began to support carrier’s data, voice, and video services with a 99.999% availability index, extending its scope to the intercontinental range.
- Data center switches: With upgrades supporting EVPN, RDMA, and network automation, Ethernet can support millions of virtual machines and EB-level storage networks in cloud computing centers, handling nearly all network traffic from terminals to the cloud.
- Ultra Ethernet switches: The latest evolution of Ethernet, these switches have entered supercomputers and have become a new generation computing bus.
What are the key features of the fifth-generation Ultra Ethernet switch?
- Ultra-low latency: Cut-through latency is not the only aspect that matters. Due to the need for collective communication, storage and forwarding latency are equally crucial, making a high-speed packet cache a key feature for end-to-end ultra-low latency.
- Computing power: Super Ethernet is not just a network device; it’s also a formidable computing device capable of real-time processing of large model data, accelerating the training and inference of large models.
- Programmability: Super Ethernet is an open and evolving standard. Line-speed programmability will support emerging services and extend the product’s lifecycle.
- Collaboration capability: An AI data center is a distributed computing system that requires collective action and computing network collaboration to maximize efficiency.
With the advent of Ultra Ethernet, we can expect an interconnected network of CPUs, GPUs, memory, and other computing resources. This unparalleled scalability will support the interconnection of 100,000-level computing nodes and transform data centers into AI super factories, rivaling the power of supercomputers.Connection breeds intelligence, and larger connections foster greater intelligence. As the bus of AI data centers, Ultra Ethernet is poised to usher in a new era of super-powered computing.
Following the trend, the Asterfusion CX864E-N 800G switch stands out as a super Ethernet switch. Let’s dive into its internal structure and see what makes it exceptional.
Asterfusion 800G Switch Stands out as a Ultra Ethernet Switch Tailor for AI Data Center Network

Hights
- Ultra-Low Latency Switching Network: This switch achieves an industry-leading 560ns cut-through latency on 800G ports, ensuring ultra-low latency performance.
- High-Speed On-Chip Packet Cache: With over 200MB of large-capacity high-speed on-chip packet cache, it significantly reduces the store-and-forward delay of RDMA traffic during collective communication.
- Powerful CPU and Scalable Memory: Equipped with an Intel Xeon CPU and large-capacity scalable memory, it runs the continuously evolving enterprise-level SONiC-AsterNOS network operating system. This setup allows direct access to the packet cache through DMA, enabling real-time network traffic processing.
- INNOFLEX Programmable Forwarding Engine: This engine can adjust the forwarding process in real-time based on business needs and network status.
- FLASHLIGHT Traffic Analysis Engine: This refined engine measures the delay and round-trip time of each packet in real-time. It implements adaptive routing and congestion control through intelligent analysis by the CPU.
- Open API: All functions are accessible to the AI data center management system through REST API, enabling automated deployment of GPU clusters in collaboration with computing devices.
Benefits and Capabilities
This design allows the Asterfusion CX864E-N to achieve programmability and upgradeability while maintaining extreme performance. It collaborates with computing devices to create scalable and efficient GPU clusters. Additionally, it supports an open AI ecosystem, breaking the strong binding between computing devices and network devices, and reducing the construction and operating costs of AI data centers.
Asterfusion 800G Ultra Ethernet Interconnection for AIDC
RoCEv2 AI Solution with NVIDIA DGX SuperPOD

Connection Generates Intelligence: Greater connection generates greater intelligence. As the backbone of AI data centers, Ultra Ethernet seamlessly connects CPU, GPU, memory, and other computing resources to achieve unparalleled scalability. It supports interconnection of up to 100,000 computing nodes, transforming data centers into AI super factories comparable to supercomputers.
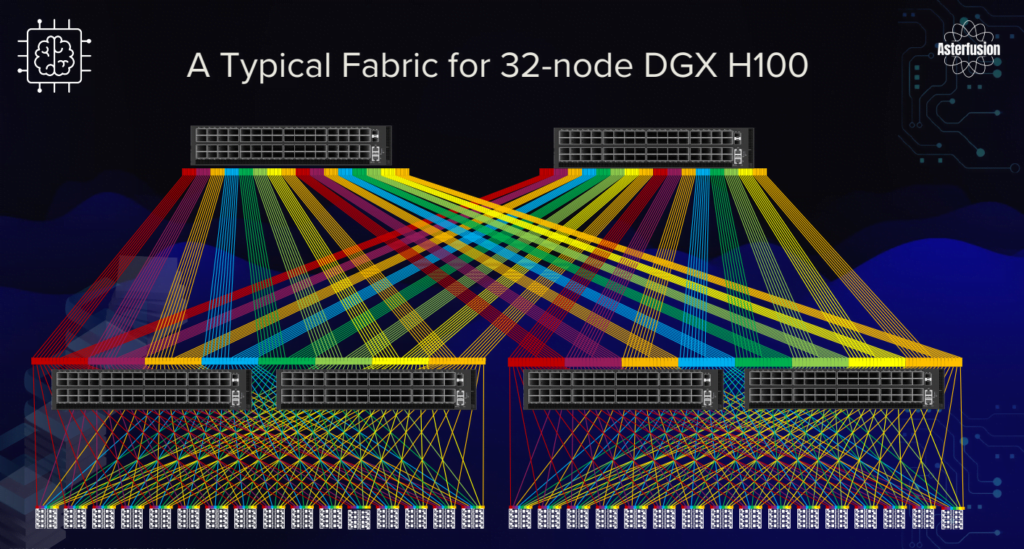
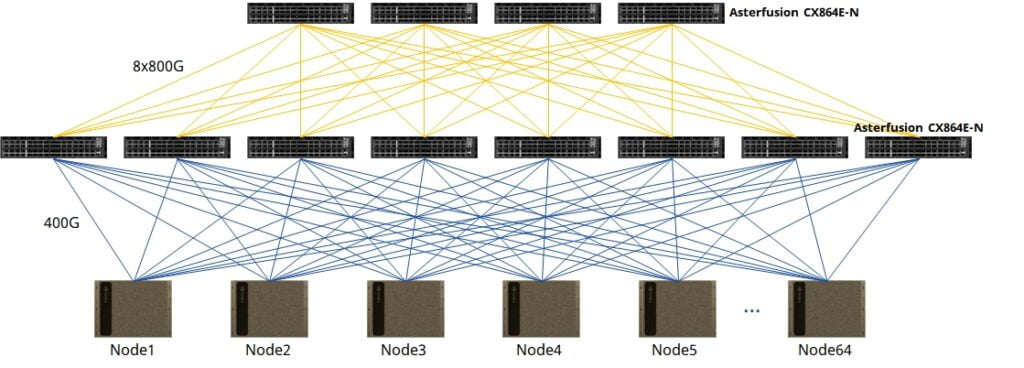
Asterfusion 800G&400G switches in 16 nodes
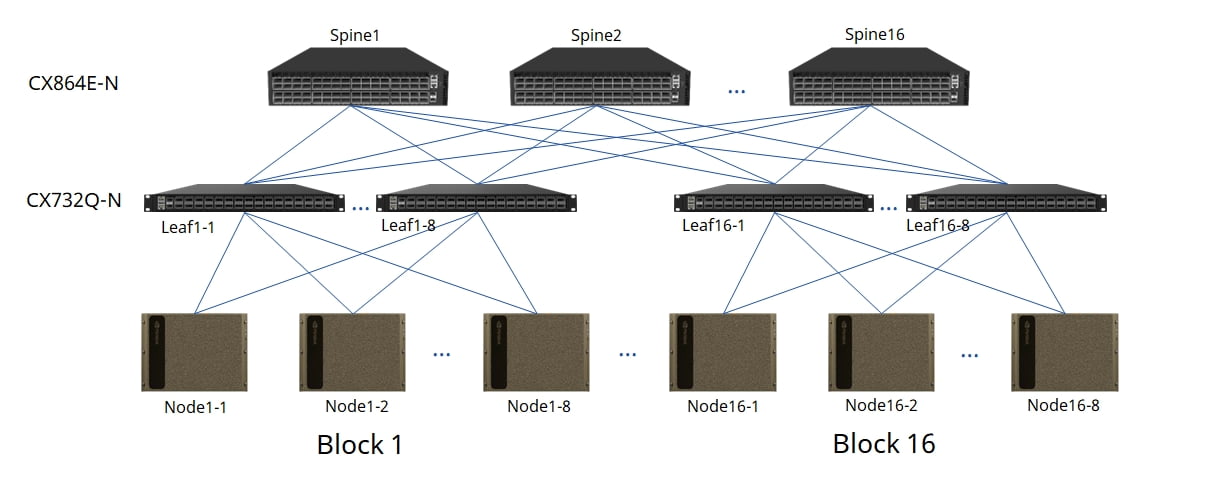
Asterfusion 800G Spine-Leaf Connectivity Solutions in 64 nodes
By leveraging these advanced features, the Asterfusion CX864E-N 800G switch is poised to redefine the landscape of AI data centers, offering unmatched performance and scalability.
Reference:
([i])https://hpl-mxp.org/results.md
([ii])https://datascientest.com/en/intel-announces-aurora-genai-its-trillion-parameter-supercomputer
([iii])https://top500.org/lists/top500/2024/06/
([iv])https://posts.careerengine.us/p/6675818ccfb4cb34fe4e7249?from=latest-posts-panel&type=title
([v])https://asterfusion.com/hpc/
([vi])https://www.ieee802.org/3/dj/projdoc/timeline_3dj_231128.pdf



